
Ein packendes Format
 Lšngst geben sich Computer-Benutzer mit stehenden Bildern nicht mehr zufrieden.
Das Format MPEG ist ein standardisiertes Format, das neben Videos auch die
Aufzeichnung und Wiedergabe von Audiodaten in CD-Qualitšt ermŲglicht.
Es zeichnet sich unter anderem durch ausgefeilte Komprimierungstechniken aus.
FŁr fast alle Funktionen stehen Programme zur VerfŁgung, die ohne teure
Spezialhardware auskommen (js).
Lšngst geben sich Computer-Benutzer mit stehenden Bildern nicht mehr zufrieden.
Das Format MPEG ist ein standardisiertes Format, das neben Videos auch die
Aufzeichnung und Wiedergabe von Audiodaten in CD-Qualitšt ermŲglicht.
Es zeichnet sich unter anderem durch ausgefeilte Komprimierungstechniken aus.
FŁr fast alle Funktionen stehen Programme zur VerfŁgung, die ohne teure
Spezialhardware auskommen (js).
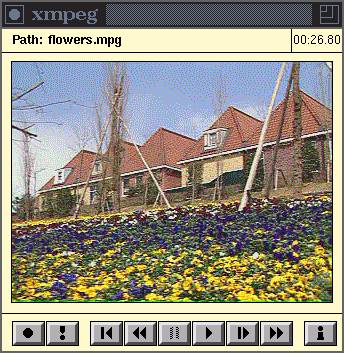
Bild 1:
Der frei verfŁgbare MPEG-Player xmpeg bietet alle
Abspielfunktionen eines Videorecorders.
{kind=link}
MPEG lšŖt sich schon heute nicht mehr aus der multimedialen Welt der Computer wegdenken. Zu verdanken ist dies dem Umstand, daŖ das Videokompressionsformat MPEG frŁhzeitig in Einklang mit Wissenschaftlern und Wirtschaft international standardisiert wurde. Dank MPEG ist die Darstellung von synchronisierten, qualitativ hochwertigem Video und Audio zur Normalitšt geworden.
MPEG heiŖt ĽMotion Picture Expert Groupę und ist die Gruppe der ISO, die sich mit der Standardisierung im Videobereich beschšftigt. Bereits im Dezember 1992 wurde ein Draft International Standard mit dem Łbersetzten Titel ĽCodierung von Bewegtbildern und assoziierten Audio fŁr digitale Speichermedien mit bis zu 1,5 MBit/sę (also fŁr die CD-ROM) vorgelegt, wenig spšter wurde das Verfahren international standardisiert (ISO 11172). Der durch die WorkGroup 11 vorgelegte Standard besteht aus drei Teilen: System, Video und Audio.
- System-behandelt Synchronisaton und Multiplexing
- Video-Codierungstechniken
- Audio-Psychoakustisches Modell
Da die digitale Darstellung eines Studio-TV-Signals eine Nettodatenrate von
166 Mbit/s erfordert und keines der bereitstehenden digitalen Medien eine
solche Datenrate bieten kann, war Kompression oberstes Gebot. Video und Audio
sind zeitabhšnge Medien, was es ermŲglicht z.B. statt der einzelnen Bilder nur
die Unterschiede zwischen aufeinanderfolgenden Bildern abzuspeichern. AuŖerdem
kann eine Verringerung des Informationsgehaltes pro Bild durch die schnelle
Bildfolge (also die teilweis Wiederholung von Bildteilen) wettgemacht werden.
Deshalb besteht keine Notwendigkeit, alle digitalen Informationen zu codieren
und MPEG ist als verlustbehaftete Codierung konzipiert.
MPEG wurde durch die Wahl der Codierung auf asymetrische Anwendungen (Fernseh-
Technik, Multimedia-Mail, etc.) zugeschnitten, das heiŖt die Herstellung des
digitalen Datenstroms erfordert wesentlich mehr Ressourcen als dessen
Konsumierung. Im Gegensatz dazu ist z.B. der ISDN-Bildtelefonstandard H.261 ein
synchrones Verfahren; sowohl auf Sender- als auch auf Empfšngerseite wird die
gleiche Hard- oder Software vorausgesetzt.
MPEG ist nicht die optimale Videocodierung, allerdings ist sie der einzig
internationale Konsens in diesem Bereich und findet, auch dank seiner
Verwandschaft mit den Telekommunikations-Standards (H.261, S-VHS) sowie seiner
Kompatibilitšt zu allen CD-ROM-Formaten (CD-Interactive, CD-Video, ISO-9660)
weite Verbreitung.
Bei einem zu erzielenden Datendurchsatz von 1,5 Mbit/s werden maximal 1.2Mbit/s
fŁr den Video- und 386 Kbit/s fŁr den Audiobereich verwendet. Durch das
Codierungverfahren, sind Einzelbildzugriff, schnelles suchen (Positionierung
auf I-Frames), rŁckwšrts spielen und die Editierbarkeit des Datenstroms
gegeben. Ein MPEG-Stream lšŖt sich in mindestens 32 Video- und Audio-Spuren
und 2 Systemspuren zur Synchronisation codieren. Zur Synchronisation werden
die Video- und Audiospuren in sog. Frames zerlegt und im Systemstream
entsprechend der gewŁnschten Datenrate verschachtelt (multiplexing). Die GrŲŖe
der Frames kann hierbei fŁr die verschiedenen CD-Rom Formate variiert werden
(siehe Bild 2).

Bild 2: Die schematische Darstellung des Multiplexers und Packatizers zeigt, wie in einem MPEG-Film Audio- und Videopakete ineinander gescahchtelt werden.
Im Gegensatz zum Festbildformat JPEG werden in MPEG feste Quantisier- und
Huffmann-Tabellen verwendet. Diese sind zwar nicht fŁr jede Video-‹bertragung
optimal, kŲnnen dann jedoch auch in Hardware codiert werden. Quantisierung
steht hier fŁr die Anzahl der mŲglichen Bits, die zur Codierung eines
Bildpunktes verwendet werden kŲnnen. Die Huffmann-Codierung reduziert sich
wiederholende Bitfolgen auf Eintršge in Symboltabellen, wobei sich hšufig
wiederholende Bitfolgen durch mŲglichst kurze Symbole ersetzt werden.
Feststehende Tabellen sind zwar nie optimal, jedoch unerlšŖlich fŁr die
Fernsehtechnik und Hardware-Integration. Die BildgrŲŖe ist variabel (in
16-Pixel-Schritten) und kann maximal horizontal 720 Pixel und vertikal 576
Pixel betragen, dies ist die AuflŲsung eines normalen S-VHS Signals.
Ein MPEG-Video-Stream wird durch Aneinanderreihung von Intra- (I), Predicted-
(P), und Bidirectional-Frames (B) beschrieben. I-Frames sind komplett im JPEG-
Format abgelegt, in P-Frames werden nur die Differenzen zu einem I-Frame
codiert, ein B-Frame codiert die mittleren Differenzen eines I- und eines
P-Frames (siehe Bild 3). Dieses Verfahren nennt man Intra/Delta-Frame-
Codierung. Jeder Frame wird wiederum in drei Planes, eine Luminanz-Plane
(Grauwerte, Y) und zwei Chrominanz-Planes (Farbwerte, Cr und Cb), zerlegt.
einem MPEG-Film Audio- und Videopakete ineinander gescahchtelt werden.
Da sich gezeigt hat, daŖ das menschliche Auge Farbwerte in einer geringeren
AuflŲsung als Helligkeitswerte wahrnimmt, wird der gšngige RBG-Farbraum (Rot-
GrŁn-Blau) bei den digitalen Bildstandards in drei Planes umgewandelt, eine
Luminanz-Plane (Grauwerte, Y) und zwei Chrominanz-Planes (Farbwerte U/V,
manchmal auch Cr/Cb). Die Farbwert-Planes kŲnnen dann von ihrer Kantenlšnge
halbiert werden (das ist dann ein Viertel der Flšche !). Dies reduziert die
Datenmenge enorm, ist jedoch ein Datenverlust. Diese Art der Codierung nennt
man den 4:1:1 YUV-Farbraum.
Alle Planes werden in 8x8 Pixel-BlŲcke aufgeteilt. Jeder dieser BlŲcke wird
mittels einer Discrete-Cosine-Transformation (DCT) codiert, dabei wird der
erste Wert jedes Blocks als DC-Koeffizient (DC) bezeichnet; die restlichen
Differenzwerte als AC-Koeffizienten. DC's werden untereinander auch als
Differenzen gespeichert.
Von den zur VerfŁgung stehenden Transformationen hat sich die DCT, die von der
diskreten Fourier Transformation abgeleitet ist, als besonders effizient
erwiesen. Eine auf einen 8x8 Pixelblock angewendete DCT ergibt wiederum einen
8x8 Pixelblock. Die Koeffizienten der DCT lassen sich als Spektrum des 8x8
Eingabeblock interpretieren. Wšhrend die Energie des Bildsignals zufšllig
verteilt sein kann, konzentriert sich die Energie des korrespondierenden
DCT-Blocks vorzugsweise auf Koeffizienten mit niedrigen Frequenzen. Werden
die Koeffizienten im Zick-Zack durchnummeriert, ergeben sich als zu
speichernde Werte ein DC-Koeffizient, dann wenige niedrige AC-Koeffizienten
und viele AC-Koeffizienten nahe Null. Die DCT ist ein verlustfreies Verfahren,
da die Codierung komplett umkehrbar ist und komprimiert selber nicht. Die DCT-
Werte eignen sich jedoch optimal, um sie einer Entropie-Codierung zuzufŁhren.
Die Entropie-Codierung (oder Lauflšngen-Codierung) speichert bei
aufeinanderfolgenden gleichen Werten einmal den Wert und dann die Anzahl der
Werte. Kommt im Datenstrom also hintereinander siebenmal die 2, wird nur die
7 und die 2 codiert. Die Entropie-Codierung generiert wiederum sich
wiederholende Byte-Folgen, die mit dem Huffman-Verfahren, optimal
weiterkomprimiert werden kŲnnen. Hšufige Byte-Folgen werden durch kurze
Bit-Sequenzen ersetzt. Entropie- und Huffman-Codierung sind ebenfalls
verlustfrei und beide Verfahren werden auch bei allen normalen
Kompressionsmethoden (compress, zip) eingesetzt. Wie sich gezeigt hat,
ergibt bei Videoinformationen jedoch erst die Kompression der mit einer
DCT umgewandelten Daten eine optimale Kompressionsrate.
Zusštzlich kŲnnen Frames auch als Verweise der MacroblŲcke auf gleiche, in
vorherigen Frames gespeicherten BlŲcken codiert werden (hier bezieht man sich
jedoch auf 16x16 Pixel-BlŲcke). Dieses Verfahren nennt man Motion-Compensation.
Die hohe Kompressionsrate von um die 80:1 (VHS-Video nach MPEG-1
Systemdatenstrom) ergibt sich erst durch die Kombination aller aufeinander
abgestimmter Kompressiontechniken: 4:1:1 YUV-Farbraum, Intra/Delta-Frame-
Codierung, DCT, Motion Compensation, Entropie- und Huffmann-Codierung.
Der Audio-Teil des MPEG-Draft beschreibt Mechanismen und Algorithmen, mit
denen die digitale Speicherung von Audiosignalen auf kostengŁnstigen
Speichermedien auf der einen Seite und die digitale ‹bertragung von
Audiosignalen auf Kanšlen mit begrenzter Kapazitšt auf der anderen Seite
ermŲglicht wird. Bei all dem Zielstreben steht jedoch die Erhaltung der
Qualitšt in einem bestimmten Bereich im Vordergrund. Im Audio-Bereich wird
eine der Compact Disc nahekommende Qualitšt erreicht. Viele lassen sich immer
noch durch das stetige Flimmern der Videobilder blenden und haben vŲllig
Łbersehen, daŖ die eigentliche Multimedia-Revolution soeben im Audiobereich
stattgefunden hat. Die ‹bertragung von Musik und Sprache Łber z.B.
Ethernetnetze und die Speicherung von mehr als 10 Stunden Audio auf einer
CD-Rom, und das alles in CD-Qualitšt, kann nicht hoch genug eingeschštzt
werden. Selbst die ‹bertragung Łbers Internet ist bereits mŲglich und
realisiert.
Layer II ist im
Verhšltnis zum Layer I komplexer aber im Bezug auf die Codierung auch
effizienter.
MPEG-2 ist die Erweiterung von MPEG-1, die RŁcksicht auf die
hardwaretechnischen Neuerungen und Erfordernisse nimmt. MPEG-2 ist nicht mehr
zugeschnitten auf die Datenraten der CD-ROM und speziell fŁr den Einsatz in
der professionellen Videotechnik gedacht. Besonders ist hierbei die neu
hinzugefŁgte Funktionalitšt der Scalability zu nennen. Sie soll eine
Anpassung der Ausgabequalitšt an die zur VerfŁgung stehende Hardware
ermŲglichen. Der Decoder hat dazu die Fšhigkeit, Teile des Datenstroms zu
ignorieren und mit dem decodierten Teil eine Ľbrauchbareę Video und Audio-
Ausgabe zu produzieren. Insbesondere wird dadurch bei einem HDTV-codierten
16:9-Bild die Abwšrtskompatibilitšt zu einem Ľnormalemę 4:3 Fernsehbild
garantiert. Weitere Features von MPEG-2 sind: angepaŖte Bandbreite bis 10
MBit/s fŁr Satelliten-Broadcasts, Electronic Cinema und Digital Home
Television, MPEG-1 and H.261 Abwšrtskompatibilitšt, Multi-Channel-Mode,
Dolby Surround, intelligente Schachtelung von Video und Audio zur Vermeidung
von Synchronisationsverlusten (auto-sync.) und VerschlŁsselung.
Digital Video Interactive (DVI) ist ein frŁher Versuch der Firma Intel
(in Zusammenarbeit mit IBM) einen Standard in der Kompression von
kontinuierlichen Medien durchzusetzen. Intel kaufte 1988 die Rechte an DVI
vom David Sarnoff Research Center. Ein Jahr spšter stellte man das erste
Produkt vor. Es war ein 386er PC mit sieben Steckkarten. Zwei
Kompressionsformate werden von DVI unterstŁtzt: RTV (Real Time Video) wurde
vom Benutzer mittels seiner lokalen Hardware gebraucht; PLV (Production
Level Video) erreichte Kompressionsraten von 160:1, konnte jedoch nur von
authorisierten Firmen erzeugt werden und erforderte teure Spezialhardware.
Bis jetzt ist DVI weder auf anderen Rechnerwelten noch ohne extreme
HardwareunterstŁtzung denkbar. AuŖerdem scheint sich Intel mit dem neuen
Verfahren ĽIndeoę mittlerweile gegen das eigene DVI gestellt zu haben.
Trotzdem hat die Firma Fast kuerzlich ein DVI-Board produziert (eigentlich
handelt es sich um die sogenannte Screen Machine von Fast mit einer neuen
Software unter Windows 3.1 und einem DVI-Kompressionschip).
Das in das Apple Betriebssystem integrierte, zeitbasierte Format Quicktime
wird oft als Konkurrenz zu MPEG gesehen, der Vergleich hinkt jedoch stark.
Quicktime ist ein Format, um digitale Daten und deren zeitabhšngige
Pršsentation zu codieren und zu synchonisieren. In Quicktime kŲnnen sowohl
Video, als auch Ton, Text oder Programme und Geršte gesteuert, Effekte
definiert und verschiedene Spuren synchonisiert werden. Quicktime selber
ist kein Komprimierungsformat, innerhalb eines Quicktime-Datenstromes werden
jedoch die verschiedensten (auch komprimierten) Datenformate genutzt: z.B.
das Videokomprimierungsverfahren Cinepak, welches auch fŁr AVI lizensiert
wurde. AuŖerdem ist ein MPEG-Codec zur Einbettung in Quicktime erhšltlich.
Hier sollte also eher Cinepak mit MPEG verglichen werden.
AVI (Audio-Video-Interlaced) scheint Microsofts Antwort auf Apple's Quicktime
zu sein, kann dies jedoch nicht leisten. AVI stellt unter der
Benutzeroberflšche MS-Windows 3.1 mehrere Utilities und Driver zu
VerfŁgung, die es erlauben, kleinste Video-Sequenzen (20 Sekunden 160x120
Pixel bei 8 Bit Farbe nehmen immerhin 2
MB Daten ein) per Hardware zu digitalisieren, zu editieren, komplett in die
Windows-Umgebung zu integrieren, mit von Hardware gesampeltem Audio zu
synchonisieren und natŁrlich auch alles zusammen abzuspielen. Insbesondere
wird hier ein Kompressionverfahren der Firma Intel (Indeo) eingesetzt, das
ein zweidimensionales Ľscalingę des Video-Filmes erlaubt. Entsprechend der
Microsoft-Philosophie sind die Softwarecodecs austausch- und einfach in das
AVI-Format integrierbar. Das groŖe Manko von AVI ist die noch ungenŁgende
Kompression. Da AVI bis jetzt auch nur auf einer Hardware-Platform
implementiert ist (und AVI kein internationaler Standard ist) wird sich
AVI zwar einer groŖen Verbreitung in der Intel/Microsoft-Welt erfreuen,
jedoch wohl kaum in den Bereich der Telekommunikation vordringen kŲnnen.
Mittlerweile werden die meisten hochwertigen PC-Videokarten bereits mit
HardunterstŁtzung fŁr AVI und MPEG geliefert, auŖerdem ist auch ein MPEG-
Codec zur Integration in AVI-Videos erhšltlich.
Das Datenkompressionformat MPEG-1 ist entwickelt worden, um mit Hilfe von
zusštzlichen, preiswerten Spezial-Chips den Datenstrom in Echtzeit zu
decodieren. Mittlerweile sind diese MPEG-Karten im PC-Bereich weit verbreitet,
andere Plattformen ziehen langsam nach. Vorreiter waren hier die Firma Sigma
Designs und Phillips, die die ersten MPEG-Decoder-Chips herstellten, letztere
insbesondere fŁr ihre CD-I-Player.
Zusštzlich zu den HardwarelŲsungen existiert fŁr fast alle Aufgaben Software,
die meist als Quelltext in C bzw. C++ zur VerfŁgung steht und auf fast allen
Unix-Plattformen lauffšhig ist. So gibt es Tools fŁr das Komprimieren,
Abspielen, Multi- und Demultiplexen. Wichtig sind die Encoder-/Decoder-
LŲsungen der Universitšten Berkeley und Stanford. Der unter der GPL
(GNU Public Licence) verbreitete Code beider Pakete ist in Dutzende Player
anderer Systeme eingebaut worden. In der neuesten Version des Berkeley-
Toolkits sind nicht nur Encoder und Decoder sondern auch diverse Analysetools
und das Statistiktool mpegstat der TU-Berlin enthalten
(ftp://ftp.cs.berkeley.edu/multimedia/mpeg). Der Stanford-Encoder glšnzt
durch die MŲglichkeit der Verteilung auf mehrere Maschinen im Netz, was bei
ausreichender Anzahl Echtzeit-Encoding ermŲglicht.
Weite Verbreitung hat xmplay von JŁrgen Meyer und Frank Gadegast (TU-Berlin)
gefunden, ein X11-Frontend auf Basis des Berkeley-Decoders mit zusštzlichen
Features wie schneller Suchlauf, Vor- und ZurŁckspulen. (Source-Code und
weitere Infos unter http://www.mpeg1.de/xmplay.html). FŁr Stanford-Encoder glšnzt
Windows empfiehlt sich vmpeg Version 1.7 von Stefan Eckhard (TU MŁnchen),
das auf den meisten Mailboxen und FTP-Servern gefunden werden kann. Es
unterstŁtzt den kompletten MPEG-Datenstrom (Video, Audio und System), sowie
das direkte Abspielen von CD-Is und Video-CDs.
Die im MPEG-Bereich sehr aktive Firma Xing Technologies hat sowohl fŁr
Windows als auch fŁr SunOS und Solaris ein Client/Server-Paket namens
StreamsWorks (
http://www.xingtech.com/) herausgebracht.
Hiermit werden
bereits heute Łber Ľnormaleę Internet-Leitungen Programme von Radiostationen,
Life-Musik oder Konferenzen in Echtzeit und CD-Qualitšt Łbertragen. Die
Server passen sich dabei bei der Codierung in Echtzeit der reellen
‹bertragungsleistung an, um Aussetzer und VerzŲgerungen zu vermeiden. Die
VideoŁbertragung mittels MPEG ist zwar bereits in StreamWorks integriert,
erfordert jedoch mehrere ISDN-B-Kanšle, die ‹bertragung ist hier nicht mehr
Łber das Internet mŲglich.
Alle hier genannten Utilities und deren Source-Code, sowie Beispiel-Streams
(Audio und Video) sind z.B. auf der CD ĽThe Internet MPEG CD-ROMę
zusammengestellt.
Zum SchluŖ beibt festzustellen, daŖ das MPEG-Kompressionverfahren dank
seiner Standardisierung sowohl im Computer- als auch im Consumer-Markt
(digitales Fernsehen, CD-I und nicht zu vergessen die Spieleconsolen von
Amiga und Sony) bereits eine feststehende GrŲŖe ist. Die Codierung anderer
Verfahren mag zwar noch effizienter sein und auch mehr Funktionalitšt bieten,
in Zeiten der globalen Vernetzung ist jedoch Platformunabhšngigkeit und
Kompatibilitšt der stšrkere Trumpf. (Frank Gadegast /js)
ĽThe Internet MPEG CD-Romę
ĽStreamWorksę
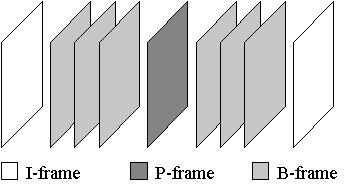
Bild 3: Nur die I-Frames eines Video-Streams sind als JPEG-Bilder abgelegt,
wšhrend in P- und B-Frames nur Differenzen gespeichert sind.
Die Darstellung eines stereophonen Audiosignals im Studioformat erfordert
eine Abtastfrequenz von 48 KHz und eine gleichfŲrmige Quantisierung von 16
Bit pro Abtastwert. Daraus ergibt sich eine Datenrate von 768 KBit/s fŁr
ein Monosignal, als Produkt der Multiplikation der 48 KHz mit den 16 Bit
pro Abtastwert. Daraus resultierend ergibt sich fŁr ein Stereosignal eine
Datenrate von 2x768 KBit/s, also ca. 1,5 MBit/s. Als Vergleich dazu wird auf
einer Compact Disc mit einer Abtastfrequenz von 44,1 KHz bei der gleichen
Quantisierung von 16Bit pro Abtastwert gearbeitet, wodurch sich eine
Datenrate von circa 706 KBit/s (Mono) ergibt.
Im MPEG-Audio-Standard werden drei Abtastfrequenzen verwendet, 32 KHz, 44.1
KHz und 48 KHz. Aber im Gegensatz zu den oben beschriebenen Fšllen ergeben
sich hier im Endeffekt Datenraten zwischen 32 KBit/s und 192 KBit/s fŁr ein
Monosignal. FŁr ein Stereosignal liegen sie zwischen 128 KBit/s und 384 KBit/s.
Mit einer Datenrate unter 128 KBit/s (mono 64 KBit/s) kŲnnen leider noch keine
zufriedenstellende Ergebnisse erzielt werden.
Das Ziel des Standards ist es, mit einer von 1,5 MBit/s im Studioformat auf
256 KBit/s reduzierten Datenrate eine der Compact Disc ebenbŁrtige Qualitšt
zu erreichen, wobei auch bei niedrigeren Datenraten wie 192 KBit/s bis
hinunter zu 128 KBit/s noch akzeptable Qualitšten erzielt werden sollen.
Das menschliche GehŲr ist im allgemeinen bei StŲrungen im Audio-Bereich
empfindsamer als im visuellen Bereich, d.h. kurzzeitiges Rauschen und
Knacken ist stŲrender als z.B. Flimmern im visuellen Bereich, daher wird
eine der CD vergleichbare Qualitšt angestrebt.
Innerhalb der Codierung sind vier Modi zu unterscheiden. Single Channel
Coding fŁr Monosignale, Dual Channel Coding zur Codierung von z.B.
bilingualen Monosignalen (wie z.B. Zweikanalton im Bereich des TV),
Stereo Coding zur Codierung eines Stereosignals, bei dem die beiden Kanšle
separat codiert werden. Zusštzlich ist das Joint Stereo Coding zu nennen,
das ebenso wie das Stereo Coding zur Codierung eines Stereosignals benutzt
wird. Bei diesem Verfahren wird die Datenredundanz und -irrelevanz zwischen
den beiden Kanšlen ausgenutzt und somit eine Datenverminderung erreicht.
Das digitale Eingangssignal wird in 32 gleichfŲrmige Spektralkomponenten
(Frequenzgruppen, Teilbšnder) zerlegt, dieses Grundprinzip entspricht dem
Vorgang im menschlichen GehŲr (Psychoakustik). Der Vorgang wird als Zeit-
Frequenzbereichs-Umsetzung bezeichnet. Die Spektralkomponenten werden dann
in Abstimmung auf die Wahrnehmungseigenschaften des menschlichen GehŲrs
codiert. Diese Codierung wird von einem der drei definierten Layer
durchgefŁhrt.
Sowohl Quantisierung als auch Codierung werden unter Einbeziehung einer
Maskierungsschwelle realisiert. Diese Maskierungsschwelle wird vom
Psychoakustischen Modell fŁr jede Komponente individuell nach einer diskreten
Fourier Transformation berechnet und gibt die maximal erlaubte
Quantisierungsfehlerleistung an, mit der noch codiert werden darf, ohne daŖ
eine Wahrnehmung dieses Fehlers durch das menschliche GehŲr befŁrchtet werden
muŖ. Die oben erwšhnten drei Layer des MPEG-Audio-Standard arbeiten alle nach
dem beschriebenen Grundprinzip. Die Zerlegung des Eingangssignals und der
Codierung unterscheidet sich jedoch sowohl in der benŲtigten Rechenleistung
als auch in der erreichten Kompressionsrate (siehe
Bild 4).
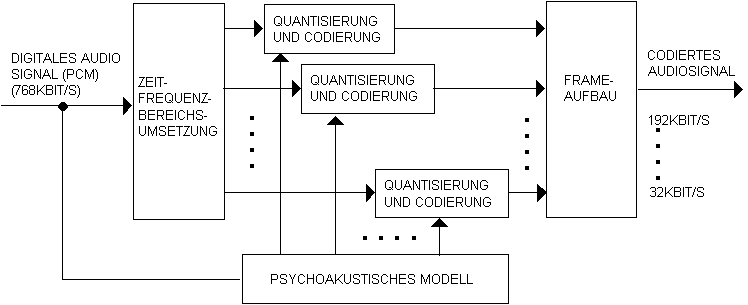
Bild 4: Das psychoakustische Modell erlaubt eine verlustbehaftete
Komprimierung, die sich am menschlichen GehŲr orientiert.
Der Layer III besitzt die grŲŖte Komplexitšt und zugleich die hŲchste
Effizienz. Er kann mittlerweile auf hochwertigen Computern (Pentium oder
Workstations) auch in Echtzeit in Software decodiert werden. Im Unterschied
zu Layer I und II verwendet dieser Layer analog zur Umsetzung im Videoteil
eine Modified Discrete Cosine Transformation (MDCT), die es erlaubt die
Anzahl der notwendigen Quantisierungwerte optimal zu errechnen. Laute,
niederfrequente Signale Łberdecken dabei leise, hochfrequente, die letzeren
mŁssen dann also nicht mit der vollen Bit-Tiefe, sprich Quantisierung,
codiert werden. Die Art der Generierung der Quantisierungswerte mit Hilfe
der MDCT wird Psychoakustisches Modell genannt und wurde durch langwieriger
HŲrtests von Musikern, Tontechniker und anderen Spezialisten optimiert.
Wie im Videoteil wird zusštzlich eine Entropie- und Huffmann-Codierung
vorgenommen, die die Werte nach der Umsetzung durch die MDCT optimal
komprimieren. Die CD-Qualitšt wird hierbei mit der selben Datenrate wie in
Layer II erreicht (256 KBit/s). Seine Stšrke zeigt die Codierung nach Layer
III erst bei niedrigeren Datenraten, bei denen immer noch eine beeindruckende
Qualitšt erzielt werden kann.
Insgesamt erhšlt man bei der MPEG-Audiokomprimierung als sehr nŁtzlichen
Nebeneffekt die Rauschfreiheit, d.h. es sind keine zusštzlichen Verfahren
zur Geršuschminderung wie z.B. das Dolby-System nŲtig.
Die Layer I und II sind bereits vollstšndig als integrierte Schaltungen
realisiert. Die Layer I Codierung wurde bereits seit den DCC-Recordern
(Digital-Compact-Cassette) verwendet. Die Layer II Codierung wird vom
europšischen DAB (Digital Audio Broadcasting) System verwendet werden.
ZukŁnftiges Ziel dŁrfte es sein, mit dem Layer III die CD-Qualitšt schon
bei einer Datenrate von 2x64kbit/s zu erreichen, hierzu wird eine ideale
Realisierung des Joint Stereo Coding notwendig sein. Dies ist in naher Zukunft
zu erwarten.
Die Echtzeitcodierung ist, da sich MPEG durch ein asynchrones
Codierungsverhalten auszeichnet, extrem aufwendig und nur durch mehrere
hochspezialisierte Bausteine realisierbar. Die Firma OptiBase stellte die
ersten Codierer-LŲsungen fŁr den PC vor. Sun hat die SunVideo-Karte
entwickelt, eine generelle Grabber-Karte, die den von der Kamera oder
Videorecorder eintreffenden Bilderstrom in wenigen festen AuflŲsungsstufen
digitalisiert und in Echtzeit unkomprimiert, mit der Sun typischen
Komprimierung CellB oder mit MPEG komprimiert ablegen kann. Diese preisgŁnstige
Variante erzeugt jedoch keine SystemdatenstrŲme. Audio kann nur im
Sun-Audio-Format Ķlaw aufgenommen und synchronisiert werden.
Als Audio-Encoder steht die Beispielimplementierung der CCITT namens musicio
zur VerfŁgung die jedoch nicht geschwindigkeitsoptimiert ist. Als Player hat
maplay -- ein Echtzeitdekoder fŁr fast jedes Unixderivat -- groŖe Verbreitung
gefunden. Die C++-Implementierung glšnzt durch Echtzeitdekodierung eines
Stereo-MPEG-Audio Signals auf Sun- und SGI-Rechnern, sowie auf Pentium-PCs.
FŁr neue Audio-Hardware kann der Code recht einfach um neue Audio-Interface-
Klassen erweitert werden. Portierungen auf Mac und PC sind vorhanden. Ein
TclTk-basiertes Interface dafŁr ist soeben in Arbeit (Binaries und Quelltext
bekommt man unter ftp://ftp.cs.tu-berlin.de/incoming/maplay/). FŁr Windows
sollte man sich als Audio-Player mpgaudio von Xing Technologies,
fŁr den Mac das Programm MPEG/CD besorgen.
Die wohl grŲŖte Sammlung freier MPEG-Videos findet man im niederlšndischen
MPEG-Archiv unter http://w3.eeb.ele.tue.nl/mpeg/index.html, die besten
Audio-Files findet man auf dem IUMA-Archiv (http://www.iuma.com): Mehr
als 500 Underground-Bands pršsentieren hier mindestens einen kompletten
Song. Als weitere Adresse im Web ist das MPEG-Archiv bei PowerWeb zu
nennen (http://www.mpeg1.de). Dort findet man die
ĽFrequently Asked Questionsę (FAQs) zu MPEG. AuŖerdem enthšlt es die
wichtigsten Utilities und mehr als 200 Links zum Thema. Anlšsse, wie z.B.
die ReichstagverhŁllung von Christo werden dort mit MPEG-Filmen dokumentiert.
Nšhere Informationen:
PHADE Software
http://www.powerweb.de/phade/
Tel. (030) 344 23 66
Xing Technologies
http://www.xingtech.com
© 1995 by Frank Gadegast/Juergen Schmidt/AWi Verlag
Published in UNIXopen 12/95.
All rights reserved.