MPEG-FAQ 4.1: What is MPEG-2?
MPEG-FAQ 4.1:



What is MPEG-2?
MPEG-2 FAQ
version 3.7 (May 11, 1995)
by Chad Fogg (cfogg@chromatic.com)
The MPEG (Moving Pictures Experts Group) committee began its life in
late 1988 by the hand of Leonardo Chairiglione and Hiroshi Yasuda with
the immediate goal of standardizing video and audio for compact discs.
Over the next few years, participation amassed from international
technical experts in the areas of Video, Audio, and Systems, reaching
over 200 participants by 1992.
By the end of the third year (1990), a syntax emerged, which when
applied to code SIF video and compact disc audio samples rates at a
combined coded bitrate of 1.5 Mbit/sec, approximated the perceptual
quality of consumer video tape (VHS). After demonstrations proved that
the syntax was generic enough to be applied to bit rates and sample
rates far higher than the original primary target application, a second
phase (MPEG-2) was initiated within the committee to define a syntax
for efficient representation of broadcast video. Efficient
representation of interlaced (broadcast) video signals was more
challenging than the progressive (non-interlaced) signals coded by
MPEG-1. Similarly, MPEG-1 audio was capable of only directly
representing two channels of sound. MPEG-2 would introduce a scheme to
decorrelate mutlichannel discrete surround sound audio.
Need for a third phase (MPEG-3) was anticipated in 1991 for High
Definition Television, although it was later discovered by late 1992
and 1993 that the MPEG-2 syntax simply scaled with the bit rate,
obviating the third phase. MPEG-4 was launched in late 1992 to explore
the requirements of a more diverse set of applications, while finding a
more efficient means of coding low bit rate/low sample rate video and
audio signals.
Today, MPEG (video and systems) is exclusive syntax of the United
States Grand Alliance HDTV specification, the European Digital Video
Broadcasting Group, and the high density compact disc (lead by rivals
Sony/Philips and Toshiba).
What is MPEG video syntax ?
MPEG video syntax provides an efficient way to represent image
sequences in the form of more compact coded data. The language of the
coded bits is the syntax. For example, a few tokens can represent an
entire block of 64 samples. MPEG also describes a decoding
(reconstruction) process where the coded bits are mapped from the
compact representation into the original, raw format of the image
sequence. For example, a flag in the coded bitstream signals whether
the following bits are to be decoded with a DCT algorithm or with a
prediction algorithm. The algorithms comprising the decoding process
are regulated by the semantics defined by MPEG. This syntax can be
applied to exploit common video characteristics such as spatial
redundancy, temporal redundancy, uniform motion, spatial masking, etc.
MPEG Myths
A brief summary myths.
1. Compression Ratios over 100:1
Articles in the press and marketing literature will often make the
claim that MPEG can achieve high quality video with compression ratios
over 100:1. These figures often include the oversampling factors in
the source video. In reality, the coded sample rate specified in an
MPEG image sequence is usually not much larger than 30 times the
specified bit rate. Pre-compression through subsampling is chiefly
responsible for 3 digit ratios for all video coding methods, including
those of the non-MPEG variety.
2. MPEG-1 is 352x240
Both MPEG-1 and MPEG-2 video syntax can be applied at a wide range of
bitrates and sample rates. The MPEG-1 that most people are familiar
with has parameters of 30 SIF pictures (352 pixels x 240 lines) per
second and a bitrate less than 1.86 megabits/sec----a combination
known as "Constrained Parameters Bitstreams". This popular
interoperability point is promoted by Compact Disc Video (White Book).
In fact, it is syntactically possible to encode picture dimensions as
high as 4095 x 4095 and a bitrates up to 100 Mbit/sec. With the advent
of the MPEG-2 specification, the most popular combinations have
coagulated into Levels, which are described later in this text. The
two most common are affectionately known as SIF (e.g. 352 pixels x 240
lines x 30 frames/sec), or Low Level, and CCIR 601 (e.g. 720
pixels/line x 480 lines x 30 frames/sec), or Main Level.
3. Motion Compensation displaces macroblocks from previous pictures
Macroblock predictions are formed out of arbitrary 16x16 pixel (or 16x8
in MPEG-2) areas from previously reconstructed pictures. There are no
boundaries which limit the location of a macroblock prediction within
the previous picture, other than the edges of the picture.
4. Display picture size is the same as the coded picture size
In MPEG, the display picture size and frame rate may differ from the
size (resolution) and frame rate encoded into the bitstream. For
example, a regular pattern of pictures in a source image sequence may
be dropped (decimated), and then each picture may itself be filtered
and subsampled prior to encoding. Upon reconstruction, the picture may
be interpolated and upsampled back to the source size and frame rate.
In fact, the three fundamental phases (Source Rate, Coded Rate, and
Display Rate) may differ by several parameters. The MPEG syntax can
separately describe Coded and Display Rates through sequence_headers,
but the Source Rate is known only by the encoder.
5. Picture coding types (I, P, B) all consist of the same macroblocks types.
All macroblocks within an I picture must be coded Intra (like a
baseline JPEG picture). However, macroblocks within a P picture may
either be coded as Intra or Non-intra (temporally predicted from a
previously reconstructed picture). Finally, macroblocks within the B
picture can be independently selected as either Intra, Forward
predicted, Backward predicted, or both forward and backward
(Interpolated) predicted. The macroblock header contains an element,
called macroblock_type, which can flip these modes on and off like
switches. macroblock_type is possibly the single most powerful element
in the whole of video syntax. Picture types (I, P, and B) merely enable
macroblock modes by widening the scope of the semantics. The component
switches are:
1. Intra or Non-intra
2. Forward temporally predicted (motion_forward)
3. Backward temporally predicted (motion_backward)
(2+3 in combination represent �Interpolated�)
4. conditional replenishment (macroblock_pattern).
5. adaptation in quantization (macroblock_quantizer).
6. temporally predicted without motion compensation
The first 5 switches are mostly orthogonal (the 6th is derived from the
1st and 2nd in P pictures, and does not exist in B pictures). Some
switches are non-applicable in the presence of others. For example, in
an Intra macroblock, all 6 blocks by definition contain DCT data,
therefore there is no need to signal either the macroblock_pattern or
any of the temporal prediction switches. Likewise, when there is no
coded prediction error information in a Non-intra macroblock, the
macroblock_quantizer signal would have no meaning.
6. Sequence structure is fixed to a specific I,P,B frame pattern.
A sequence may consist of almost any pattern of I, P, and B pictures
(there are a few minor semantic restrictions on their placement). It
is common in industrial practice to have a fixed pattern (e.g.
IBBPBBPBBPBBPBB), however, more advanced encoders will attempt to
optimize the placement of the three picture types according to local
sequence characteristics in the context of more global
characteristics. Each picture type carries a penalty when coupled with
the statistics of a particular picture (temporal masking, occlusion,
motion activity, etc.).
The variable length codes of the macroblock_type switch provide a
direct clue, but it is the full scope of semantics of each picture type
spell out the costs-benefits. For example, if the image sequence
changes little from frame-to-frame, it is sensible to code more B
pictures than P. Since B pictures by definition are never fed back
into the prediction loop (i.e. not used as prediction for future
pictures), bits spent on the picture are wasted in a sense (B pictures
are like temporal spackle). Application requirements also govern
picture type placement: random access points, mismatch/drift reduction,
channel hopping, program indexing, and error recovery & concealment.
The 6 Steps to Claiming Bogously High Compression Ratios:
MPEG video is often quoted as achieving compression ratios over 100:1,
when in reality the sweet spot rests between 8:1 and 30:1.
Heres how the fabled greater than 100:1 reduction ratio is derived for
the popular Compact Disc Video (White Book) bitrate of 1.15 Mbit/sec.
Step 1. Start with the oversampled rate
Most MPEG video sources originate at a higher sample rate than the
"target sample rate encoded into the final MPEG bitstream. The most
popular studio signal, known canonically as D-1 or CCIR 601 digital
video, is coded at 270 Mbit/sec.
The constant, 270 Mbit/sec, can be derived as follows:
Luminance (Y): 858 samples/line x 525 lines/frame x 30 frames/sec x
10 bits/sample ~= 135 Mbit/sec
R-Y (Cb): 429 samples/line x 525 lines/frame x 30 frames/sec x
10 bits/sample ~= 68 Mbit/sec
B-Y (Cb): 429 samples/line x 525 lines/frame x 30 frames/sec x
10 bits/sample ~= 68 Mbit/sec
Total: 27 million samples/sec x 10 bits/sample = 270 Mbit/sec.
So, our compression ratio is: 270/1.15... an amazing 235:1 !!
Step 2. Include blanking intervals
Only 720 out of the 858 luminance samples per line contain active
picture information. In fact, the debate over the true number of
active samples is the cause of many hair-pulling cat-fights at TV
engineering seminars and conventions, so it is safer to say that the
number lies somewhere between 704 and 720. Likewise, only 480 lines
out of the 525 lines contain active picture information. Again, the
actual number is somewhere between 480 and 496. For the purposes of
MPEG-1s and MPEG-2s famous conformance points (Constrained Parameters
Bitstreams and Main Level, respectively), the number shall be 704
samples x 480 lines for luminance, and 352 samples x 480 lines for each
of the two chrominance pictures. Recomputing the source rate, we arrive
at:
(luminance)
704 samples/line x 480 lines x 30 fps x 10 bits/sample ~= 104 Mbit/sec
(chrominance)
2 components x 352 samples/line x 480 lines x 30 fps x 10 bits/sample
~= 104 Mbit/sec
Total: ~ 207 Mbit/sec
The ratio (207/1.15) is now only 180:1
Step 3. Include higher bits/sample
The MPEG sample precision is 8 bits. Studio equipment often quantize
samples with 10 bits of accuracy. The 2-bit improvement to the dynamic
range is considered useful for suppressing noise in multi-generation
video.
The ratio is now only 180 * (8/10 ), or 144:1
Step 4. Include higher chroma ratio
The famous CCIR-601studio signal represents the chroma signals (Cb, Cr)
with half the horizontal sample density as the luminance signal, but
with full vertical resolution. This particular ratio of subsampled
components is known as 4:2:2. However, MPEG-1 and MPEG-2 Main Profile
specify the exclusive use of the 4:2:0 format, deemed sufficient for
consumer applications, where both chrominance signals have exactly half
the horizontal and vertical resolution as luminance (the MPEG Studio
Profile, however, centers around the 4:2:2 macroblock structure). Seen
from the perspective of pixels being comprised of samples from multiple
components, the 4:2:2 signal can be expressed as having an average of 2
samples per pixel (1 for Y, 0.5 for Cb, and 0.5 for Cr). Thanks to the
reduction in the vertical direction (resulting in a 352 x 240
chrominance frame), the 4:2:0 signal would, in effect, have an average
of 1.5 samples per pixel (1 for Y, and 0.25 for Cb and Cr each). Our
source video bit rate may now be recomputed as:
720 pixels x 480 lines x 30 fps x 8 bits/sample x 1.5 samples/pixel
= 124 Mbit/sec
... and the ratio is now 108:1.
Step 5. Include pre-subsampled image size
As a final act of pre-compression, the CCIR 601 frame is converted to
the SIF frame by a subsampling of 2:1 in both the horizontal and
vertical directions.... or 4:1 overall. Quality horizontal subsampling
can be achieved by the application of a simple FIR filter (7 or 4 taps,
for example), and vertical subsampling by either dropping every other
field (in effect, dropping every other line) or again by an FIR filter
(regulated by an interfield motion detection algorithm). Our ratio now
becomes:
352 pixels x 240 lines x 30 fps x 8 bits/sample x 1.5 samples/pixel
~= 30 Mbit/sec !!
.. and the ratio is now only 26:1
Thus, the true A/B comparison should be between the source sequence at
the 30 Mbit/sec stage, the actual specified sample rate in the MPEG
bitstream, and the reconstructed sequence produced from the 1.15
Mbit/sec coded bitstream.
Step 6. Don�t forget the 3:2 pulldown
A majority of high-end programs originates from film. Most of the
movies encoded onto Compact Disc Video were in captured and reproduced
at 24 frames/sec. So, in such an image sequence, 6 out of the 30
frames every second are in fact redundant and need not be coded into
the MPEG bitstream, leading to the shocking discovery that the actual
soure bit rate has really been 24 Mbit/sec all along, and the
compression ratio a mere 21:1 !!! Even at the seemingly modest 20:1
ratio, discrepancies will appear between the 24 Mbit/sec source
sequence and the reconstructed sequence. Only conservative ratios in
the neighborhood of 8:1 have demonstrated true transparency for
sequences with complex spatial-temporal characteristics (i.e. rapid,
divergent motion and sharp edges, textures, etc.). However, if the
video is carefully encoded by means of pre-processing and intelligent
distribution of bits, higher ratios can be made to appear at least
artifact-free.
What are the parts of the MPEG document?
The MPEG-1 specification (official title: ISO/IEC 11172 Information
technology Coding of moving pictures and associated audio for digital
storage media at up to about 1.5 Mbit/s, Copyright 1993.) consists of
five parts. Each document is a part of the ISO/IEC number 11172. The
first three parts reached International Standard in 1993. Part 4
reached IS in 1994. In mid 1995, Part 5 will go IS.
Part 1---Systems: The first part of the MPEG standard has two primary
purposes: 1). a syntax for transporting packets of audio and video
bitstreams over digital channels and storage mediums (DSM), 2). a
syntax for synchronizing video and audio streams.
Part 2---Video: describes syntax (header and bitstream elements) and
semantics (algorithms telling what to do with the bits). Video breaks
the image sequence into a series of nested layers, each containing a
finer granularity of sample clusters (sequence, picture, slice,
macroblock, block, sample/coefficient). At each layer, algorithms are
made available which can be used in combination to achieve efficient
compression. The syntax also provides a number of different means for
assisting decoders in synchronization, random access, buffer
regulation, and error recovery. The highest layer, sequence, defines
the frame rate and picture pixel dimensions for the encoded image
sequence.
Part 3---Audio: describes syntax and semantics for three classes of
compression methods. Known as Layers I, II, and III, the classes trade
increased syntax and coding complexity for improved coding efficiency
at lower bitrates. The Layer II is the industrial favorite, applied
almost exclusively in satellite broadcasting (Hughes DSS) and compact
disc video (White Book). Layer I has similarities in terms of
complexity, efficiency, and syntax to the Sony MiniDisc and the Philips
Digitial Compact Cassette (DCC). Layer III has found a home in ISDN,
satellite, and Internet audio applications. The sweet spots for the
three layers are 384 kbit/sec (DCC), 224 kbit/sec (CD Video, DSS), and
128 Kbits/sec (ISDN/Internet), respectively.
Part 4---Conformance: (circa 1992) defines the meaning of MPEG
conformance for all three parts (Systems, Video, and Audio), and
provides two sets of test guidelines for determining compliance in
bitstreams and decoders. MPEG does not directly address encoder
compliance.
Part 5---Software Simulation: Contains an example ANSI C language
software encoder and compliant decoder for video and audio. An
example systems codec is also provided which can multiplex and
demultiplex separate video and audio elementary streams contained in
computer data files.
As of March 1995, the MPEG-2 volume consists of a total of 9 parts
under ISO/IEC 13818. Part 2 was jointly developed with the ITU-T,
where it is known as recommendation H.262. The full title is:
Information Technology--Generic Coding of Moving Pictures and
Associated Audio. ISO/IEC 13818. The first five parts are organized in
the same fashion as MPEG-1(System, Video, Audio, Conformance, and
Software). The four additional parts are listed below:
Part 6 Digital Storage Medium Command and Control (DSM-CC): provides a
syntax for controlling VCR- style playback and random-access of
bitstreams encoded onto digital storage mediums such as compact disc.
Playback commands include Still frame, Fast Forward, Advance, Goto.
Part 7 Non-Backwards Compatible Audio (NBC): addresses the need for a
new syntax to efficiently de- correlate discrete mutlichannel surround
sound audio. By contrast, MPEG-2 audio (13818-3) attempts to code the
surround channels as an ancillary data to the MPEG-1
backwards-compatible Left and Right channels. This allows existing
MPEG-1 decoders to parse and decode only the two primary channels while
ignoring the side channels (parse to /dev/null). This is analogous to
the Base Layer concept in MPEG-2 Scalable video. NBC candidates include
non-compatible syntaxs such as Dolby AC-3. Final document is not
expected until 1996.
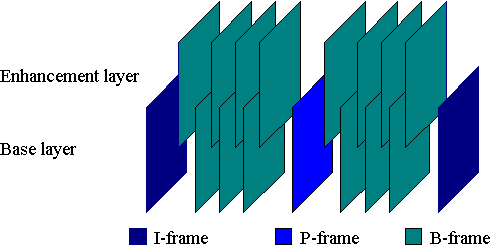
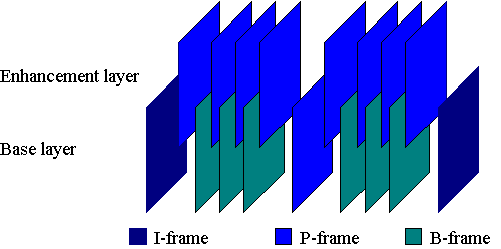
Part 8 10-bit video extension. Introduced in late 1994, this
extension to the video part (13818-2) describes the syntax and
semantics to coded representation of video with 10-bits of sample
precision. The primary application is studio video (distribution,
editing, archiving). Methods have been investigated by Kodak and
Tektronix which employ Spatial scalablity, where the 8-bit signal
becomes the Base Layer, and the 2-bit differential signal is coded as
an Enhancement Layer. Final document is not expected until 1997 or
1998. [Part 8 will be withdrawn]
 Part 9 Real-time Interface (RTI): defines a syntax for video on demand
control signals between set-top boxes and head-end servers.
What is the evolution of an MPEG/ISO document?
In chronological order:
Abbr. ISO/Committee notation Author's notation
----- ------------------------------- -----------------------------
- Problem (unofficial first stage) barroom witticism or dare
NI New work Item Napkin Item
NP New Proposal Need Permission
WD Working Draft We�re Drunk
CD Committee Draft Calendar Deadlock
DIS Draft International Standard Doesn't Include Substance
IS International Standard Induced patent Statements
Introductory paper to MPEG?
Didier Le Gall, "MPEG: A Video Compression Standard for Multimedia
Applications," Communications of the ACM, April 1991, Vol.34, No.4, pp.
47-58
MPEG in periodicals?
The following journals and conferences have been known to contain
information relating to MPEG:
IEEE Transactions on Consumer Electronics
IEEE Transactions on Broadcasting
IEEE Transactions on Circuits and Systems for Video Technology
Advanced Electronic Imaging
Electronic Engineering Times (EE Times)
IEEE Int'l Conference on Acoustics, Speech, and Signal Processing (ICASSP)
International Broadcasting Convention (IBC)
Society of Motion Pictures and Television Engineers Journal (SMPTE)
SPIE conference on Visual Communications and Image Processing
MPEG Book?
Several MPEG books are under development.
An MPEG book will be produced by the same team behind the JPEG book:
Joan Mitchell and Bill Pennebaker.... along with Didier Le Gall. It is
expected to be a tutorial on MPEG-1 video and some MPEG-2 video. Van
Nostran Reinhold in 1995.
A book, in the Japanese language, has already been published (ISBN:
4-7561-0247-6). The title is called MPEG by ASCII publishing.
Keith Jack's second edition of Video Demystified, to be published in
August 1995, will feature a large chapter on MPEG video. Information:
ftp://ftp.pub.netcom/pub/kj/kjack/and notity mpeg@powerweb.de via
MPEG is a DCT based scheme?
The DCT and Huffman algorithms receive the most press coverage (e.g.
"MPEG is a DCT based scheme with Huffman coding"), but are in fact less
significant when compared to the variety of coding modes signaled to
the decoder as context-dependent side information. The MPEG-1 and
MPEG-2 IDCT has the same definition as H.261, H.263, JPEG.
What are constant and variable bitrate streams?
Constant bitrate streams are buffer regulated to allow continuos
transfer of coded data across a constant rate channel without causing
an overflow or underflow to a buffer on the receiving end. It is the
responsibility of the Encoders Rate Control stage to generate
bitstreams which prevent buffer overflow and underflow. The constant
bit rate encoding can be modeled as a reservoir: variable sized coded
pictures flow into the bit reservoir, but the reservoir is drained at a
constant rate into the communications channel. The most challenging
aspect of a constant rate encoder is, yes, to maintain constant channel
rate (without overflowing or underflow a buffer of a fixed depth) while
maintaining constant perceptual picture quality.
In the simplest form, variable rate bitstreams do not obey any buffer
rules, but will maintain constant picture quality. Constant picture
quality is easiest to achieve by holding the macroblock quantizer step
size constant (e.g. level 16 of 31). In its most advanced form, a
variable bitrate stream may be more difficult to generate than
constant bitrate streams. In advanced variable bitrate streams, the
instantaneous bit rate (piece-wise bit rate) may be controlled by
factors such as: 1. local activity measured against activity over
large time intervals (e.g. the full span of a movie), or 2.
instantaneous bandwidth availability of a communications channel.
Summary of bitstream types
Bitrate type
Applications
constant-rate
fixed-rate communications channels like the original Compact Disc,
digital video tape, single channel-per-carrier broadcast signal, hard
disk storage
simple variable-rate
software decoders where the bitstream buffer (VBV) is the storage
medium itself (very large). macroblock quantization scale is typically
held constant over large number of macroblocks.
complex variable-rate
Statistical muliplexing (multiple-channel-per-carrier broadcast
signals), compact discs and hard disks where the servo mechanisms can
be controlled to increase or decrease the channel delivery rate,
networked video where overall channel rate is constant but demand is
variably share by multiple users, bitstreams which achieve average
rates over very long time averages
What is statistical multiplexing ?
Progressive explanation:
In the simplest coded bitstream, a PCM (Pulse Coded Modulated) digital
signal, all samples have an equal number of bits. Bit distribution in a
PCM image sequence is therefore not only uniform within a picture,
(bits distributed along zero dimensions), but is also uniform across
the full sequence of pictures.
Audio coding algorithms such as MPEG-1s Layer I and II are capable of
distributing bits over a one dimensional space, spanned by a frame. In
layer II, for example, an audio channel coded at a bitrate of 128
bits/sec and sample rate of 44.1 Khz will have frames (which consist of
1152 subband coefficients each) coded with approximately 334 bits.
Some subbands will receive more bits than others.
In block-based still image compression methods which employ 2-D
transform coding methods, bits are distributed over a 2 dimensional
space (horizontal and vertical) within the block. Further, blocks
throughout the picture may contain a varying number of bits as a
result, for example, of adaptive quantization. For example, background
sky may contain an average of only 50 bits per block, whereas complex
areas containing flowers or text may contain more than 200 bits per
block. In the typical adaptive quantization scheme, more bits are
allocated to perceptually more complex areas in the picture. The
quantization stepsizes can be selected against an overall picture
normalization constant, to achieve a target bit rate for the whole
picture. An encoder which generates coded image sequences comprised of
independently coded still pictures, such as JPEG Motion video or MPEG
Intra picture sequences, will typically generate coded pictures of
equal bit size.
MPEG non-intra coding introduces the concept of the distribution of
bits across multiple pictures, augmenting the distribution space to 3
dimensions. Bits are now allocated to more complex pictures in the
image sequence, normalized by the target bit size of the group of
pictures, while at a lower layer, bits within a picture are still
distributed according to more complex areas within the picture. Yet in
most applications, especially those of the Constant Bitrate class, a
restriction is placed in the encoder which guarantees that after a
period of time, e.g. 0.25 seconds, the coded bitstream achieves a
constant rate (in MPEG, the Video Buffer Verifier regulates the
variable-to-constant rate mapping). The mapping of an inherently
variable bitrate coded signal to a constant rate allows consistent
delivery of the program over a fixed-rate communications channel.
Statistical multiplexing takes the bit distribution model to 4
dimensions: horizontal, vertical, temporal, and program axis. The 4th
dimension is enabled by the practice of mulitplexing multiple programs
(each, for example, with respective video and audio bitstreams) on a
common data carrier. In the Hughes' DSS system, a single data carrier
is modulated with a payload capacity of 23 Mbits/sec, but a typical
program will be transported at average bit rate of 6 Mbit/sec each. In
the 4-D model, bits may be distributed according the relative
complexity of each program against the complexities of the other
programs of the common data carrier. For example, a program undergoing
a rapid scene change will be assigned the highest bit allocation
priority, whereas the program with a near-motionless scene will receive
the lowest priority, or fewest bits.
How does MPEG achieve compression?
Here are some typical statistical conditions addressed by specific
syntax and semantic tools:
1. Spatial correlation: transform coding with 8x8 DCT.
2. Human Visual Response---less acuity for higher spatial frequencies:
lossy scalar quantization of the DCT coefficients.
3. Correlation across wide areas of the picture: prediction of the DC
coefficient in the 8x8 DCT block.
4. Statistically more likely coded bitstream elements/tokens: variable
length coding of macroblock_address_increment, macroblock_type,
coded_block_pattern, motion vector prediction error magnitude, DC
coefficient prediction error magnitude.
5. Quantized blocks with sparse quantized matrix of DCT coefficients:
end_of_block token (variable length symbol).
6. Spatial masking: macroblock quantization scale factor.
7. Local coding adapted to overall picture perception (content
dependent coding): macroblock quantization scale factor.
8. Adaptation to local picture characteristics: block based coding,
macroblock_type, adaptive quantization.
9. Constant stepsizes in adaptive quantization: new quantization scale
factor signaled only by special macroblock_type codes. (adaptive
quantization scale not transmitted by default).
10. Temporal redundancy: forward, backwards macroblock_type and motion
vectors at macroblock (16x16) granularity.
11. Perceptual coding of macroblock temporal prediction error: adaptive
quantization and quantization of DCT transform coefficients (same
mechanism as Intra blocks).
12. Low quantized macroblock prediction error: No prediction error for
the macroblock may be signaled within macroblock_type. This is the
macroblock_pattern switch.
13. Finer granularity coding of macroblock prediction error: Each of
the blocks within a macroblock may be coded or not coded. Selective
on/off coding of each block is achieved with the separate
coded_block_pattern variable-length symbol, which is present in the
macroblock only of the macroblock_pattern switch has been set.
14. Uniform motion vector fields (smooth optical flow fields):
prediction of motion vectors.
15. Occlusion: forwards or backwards temporal prediction in B
pictures. Example: an object becomes temporarily obscured by another
object within an image sequence. As a result, there may be an area of
samples in a previous picture (forward reference/prediction picture)
which has similar energy to a macroblock in the current picture (thus
it is a good prediction), but no areas within a future picture
(backward reference) are similar enough. Therefore only forwards
prediction would be selected by macroblock type of the current
macroblock. Likewise, a good prediction may only be found in a future
picture, but not in the past. In most cases, the object, or
correlation area, will be present in both forward and backward
references. macroblock_type can select the best of the three
combinations.
16. Sub-sample temporal prediction accuracy: bi-linearly interpolated
(filtered) "half-pel" block predictions. Real world motion
displacements of objects (correlation areas) from picture-to-picture do
not fall on integer pel boundaries, but on irrational . Half-pel
interpolation attempts to extract the true object to within one order
of approximation, often improving compression efficiency by at least 1
dB.
17. Limited motion activity in P pictures: skipped macroblocks. When
the motion vector is zero for both the horizontal and vertical vector
components, and no quantized prediction error for the current
macroblock is present. Skipped macroblocks are the most desirable
element in the bitstream since they consume no bits, except for a
slight increase in the bits of the next non-skipped macroblock.
18. Co-planar motion within B pictures: skipped macroblocks. When the
motion vector is the same as the previous macroblocks, and no quantized
prediction error for the current macroblock is present.
What is the difference between MPEG-1 and MPEG-2 syntax?
Section D.9 of ISO/IEC 13818-2 is an informative piece of text
describing the differences between MPEG-1 and MPEG-2 video syntax. The
following is a little more informal.
Sequence layer:
MPEG-2 can represent interlaced or progressive video sequences,
whereas MPEG-1 is strictly meant for progressive sequences since the
target application was Compact Disc video coded at 1.2 Mbit/sec.
MPEG-2 changed the meaning behind the aspect_ratio_information
variable, while significantly reducing the number of defined aspect
ratios in the table. In MPEG-2, aspect_ratio_information refers to the
overall display aspect ratio (e.g. 4:3, 16:9), whereas in MPEG-2, the
ratio refers to the particular pixel. The reduction in the entries of
the aspect ratio table also helps interoperability by limiting the
number of possible modes to a practical set, much like frame_rate_code
limits the number of display frame rates that can be represented.
Optional picture header variables called display_horizontal_size and
display_vertical_size can be used to code unusual display sizes.
frame_rate_code in MPEG-2 refers to the intended display rate, whereas
in MPEG-1 it referred to the coded frame rate. In film source video,
there are often 24 coded frames per second. Prior to bitstream
coding, a good encoder will eliminate the redundant 6 frames or 12
fields from a 30 frame/sec video signal which encapsulates an
inherently 24 frame/sec video source. The MPEG decoder or display
device will then repeat frames or fields to recreate or synthesize the
30 frame/sec display rate. In MPEG-1, the decoder could only infer the
intended frame rate, or derive it based on the Systems layer time
stamps. MPEG-2 provides specific picture header variables called
repeat_first_field and top_field_first which explicitly signal which
frames or fields are to be repeated, and how many times.
To address the concern of software decoders which may operate at rates
lower or different than the common television rates, two new variables
in MPEG-2 called frame_rate_extension_d and frame_rate_extension_n can
be combined with frame_rate_code to specify a much wider variety of
display frame rates. However, in the current set of define profiles
and levels, these two variables are not allowed to change the value
specified by frame_rate_code. Future extensions or Profiles of MPEG
may enable them.
In interlaced sequences, the coded macroblock height (mb_height) of a
picture must be a multiple of 32 pixels, while the width, like MPEG-1,
is a coded multiple of 16 pixels. A discrepancy between the coded
width and height of a picture and the variables horizontal_size and
vertical_size, respectively, occurs when either variable is not an
integer multiple of macroblocks. All pixels must be coded within
macroblocks, since there cannot be such a thing as fractional
macroblocks. Never intended for display, these overhang pixels or
lines exist along the left and bottom edges of the coded picture. The
sample values within these trims can be arbitrary, but they can affect
the values of samples within the current picture, and especially future
coded pictures. In the current pictures, pixels which reside within
the same 8x8 block as the overhang pixels are affect by the ripples of
DCT quantization error. In future coded pictures, their energy can
propagate anywhere within an image sequence as a result of motion
compensated prediction. An encoder should fill in values which are
easy to code, and should probably avoid creating motion vectors which
would cause the Motion Compensated Prediction stage to extract samples
from these areas. The application should probably select
horizontal_size and vertical_size that are already multiples of 16 (or
32 in the vertical case of interlaced sequences) to begin with.
Group of Pictures:
The concept of the Group of Pictures layer does not exist in MPEG-2.
It is an optional header useful only for establishing a SMPTE time code
or for indicating that certain B pictures at the beginning of an edited
sequence comprise a broken_link. This occurs when the current B
picture requires prediction from a forward reference frame (previous in
time to the current picture) has been removed from the bitstream by an
editing process. In MPEG-1, the Group of Pictures header is mandatory,
and must follow a sequence header.
Picture layer:
In MPEG-2, a frame may be coded progressively or interlaced, signaled
by the progressive_frame variable. In interlaced frames
(progressive_frame==0), frames may then be coded as either a frame
picture (picture_structure==frame) or as two separately coded field
pictures (picture_structure==top_field or
picture_structure==bottom_field). Progressive frames are a logic
choice for video material which originated from film, where all pixels
are integrated or captured at the same time instant. Most electronic
cameras today capture pictures in two separate stages: a top field
consisting of all odd lines of the picture are nearly captured in the
time instant, followed by a bottom field of all even lines. Frame
pictures provide the option of coding each macroblock locally as either
field or frame. An encoder may choose field pictures to save memory
storage or reduce the end-to-end encoder-decoder delay by one field
period.
There is no longer such a thing called D pictures in MPEG-2 syntax.
However, Main Profile @ Main Level MPEG-2 decoders, for example, are
still required to decode D pictures at Main Level (e.g. 720x480x30
Hz). The usefulness of D pictures, a concept from the year 1990, had
evaporated by the time MPEG-2 solidified in 1993.
repeat_first_field was introduced in MPEG-2 to signal that a field or
frame from the current frame is to be repeated for purposes of frame
rate conversion (as in the 30 Hz display vs. 24 Hz coded example
above). On average in a 24 frame/sec coded sequence, every other coded
frame would signal the repeat_first_field flag. Thus the 24 frame/sec
(or 48 field/sec) coded sequence would become a 30 frame/sec (60
field/sec) display sequence. This processes has been known for decades
as 3:2 Pulldown. Most movies seen on NTSC displays since the advent of
television have been displayed this way. Only within the past decade
has it become possible to interpolate motion to create 30 truly unique
frames from the original 24. Since the repeat_first_field flag is
independently determined in every frame structured picture, the actual
pattern can be irregular (it doesnt have to be every other frame
literally). An irregularity would occur during a scene cut, for
example.
Slice:
To aid implementations which break the decoding process into parallel
operations along horizontal strips within the same picture, MPEG-2
introduced a general semantic mandatory requirement that all
macroblock rows must start and end with at least one slice. Since a
slice commences with a start code, it can be identified by
inexpensively parsing through the bitstream along byte boundaries.
Before, an implementation might have had to parse all the variable
length tokens between each slice (thereby completing a significant
stage of decoding process in advance) to know the exact position of
each macroblock within the bitstream. In MPEG-1, it was possible to
code a picture with only a single slice. Naturally, the mandatory
slice per macroblock row restriction also facilitates error recovery.
MPEG-2 also added the concept of the slice_id. This optional 6-bit
element signals which picture a particular slice belongs to. In badly
mangled bitstreams, the location of the picture headers could become
garbled. slice_id allows a decoder to place a slice in the proper
location within a sequence. Other elements in the slice header, such
as slice_vertical_position, and the macroblock_address_increment of the
first macroblock in the slice uniquely identify the exact macroblock
position of the slice within the picture. Thus within a window of 64
pictures, a lost slice can find its way.
Macroblock:
motion vectors are now always represented along a half-pel grid. The
usefulness of an integer-pel grid (option in MPEG-1) diminished with
practice. A intrinsic half-pel accuracy can encourage use by encoders
for the significant coding gain which half-pel interpolation offers.
In both MPEG-1 and MPEG-2, the dynamic range of motion vectors is
specified on a picture basis. A set of pictures corresponding to a
rapid motion scene may need a motion vector range of up to +/- 64
integer pixels. A slower moving interval of pictures may need only a
+/- 16 range. Due to the syntax by which motion vectors are signaled in
a bitstream, pictures with little motion would suffer unnecessary bit
overhead in describing motion vectors in a coordinate system
established for a much wider range. MPEG-1s f_code picture header
element prescribed a radius shared by horizontal and vertical motion
vector components alike. It later became practice in industry to have a
greater horizontal search range (motion vector radius) than vertical,
since motion tends to be more prominent across the screen than up or
down (vertical). Secondly, a decoder has a limited frame buffer size
in which to store both the current picture under decoding and the set
of pictures (forward, backward) used for prediction (reference) by
subsequent pictures. A decoder can write over the pixels of the oldest
reference picture as soon as it no longer is needed by subsequent
pictures for prediction. A restricted vertical motion vector range
creates a sliding window, which starts at the top of the reference
picture and moves down as the macroblocks in the current picture are
decoded in raster order. The moment a strip of pixels passes outside
this window, they have ended their life in the MPEG decoding loop. As
a result of all this, MPEG-2 created separate into horizontal and
vertical range specifiers (f_code[][0] for horizontal, and f_code[][1]
for vertical), and placed greater restrictions on the maximum vertical
range than on the horizontal range. In Main Level frame pictures, this
is range is [- 128,+127.5] vertically, and [-1024,+1023.5]
horizontally. In field pictures, the vertical range is restricted to [-
64,+63.5].
Macroblock stuffing is now illegal in MPEG-2. The original intent
behind stuffing in MPEG-1 was to provide a means for finer rate control
adjustment at the macroblock layer. Since no self-respecting encoder
would waste bits on such an element (it does not contribute to the
refinement of the reconstructed video signal), and since this unlimited
loop of stuffing variable length codes represent a significant headache
for hardware implementations which have a fixed window of time in which
to parse and decode a macroblock in a pipeline, the element was
eliminated in January 1993 from the MPEG-2 syntax. Some feel that
macroblock stuffing was beneficial since it permitted macroblocks to be
coded along byte boundaries. A good compromise could have been a
limited number of stuffs per macroblock. If stuffing is needed for
purposes of rate control, an encoder can pad extra zero bytes before
the start code of the next slice. If stuffing is required in the last
row of macroblocks of the picture, the picture start code of the next
picture can be padded with an arbitrary number of bytes. If the
picture happens to be the last in the sequence, the sequence_end_code
can be stuffed with zero bytes.
The dct_type flag in both Intra and non-Intra coded macroblocks of
frame structured pictures signals that the reconstructed samples output
by the IDCT stage shall be organized in field or frame order. This
flag provides an encoder with a sort of poor mans motion_type by
adapting to the interparity (i.e. interfield) characteristics of the
macroblock without signaling a need for motion vectors via the
macroblock_type variable. dct_type plays an essential role in Intra
frame pictures by organizing lines of a common parity together when
there is significant interfield motion within the macroblock. This
increases the decorrelation efficiency of the DCT stage. For
non-intra macroblocks, dct_type organizes the 16 lines (... luminance,
8 lines chrominance) of the macroblock prediction error. In combination
with motion_type, the meaning....
dct_type
motion_format
interpretation
frame
Intra coded
block data is frame correlated
field
Intra coded
block data is more strongly correlated along lines of
opposite parity
frame
Field predicted
1. a low-cost encoder which only possesses frame
motion estimation may use dct_type to decorrelate
the prediction error of a prediction which is
inherently field by characteristic
2. an intelligent encoder realizes that it is more bit
efficient to signal frame prediction with field
dct_type for the prediction error, than it is to signal
a field prediction.
field
Field predicted
A typical scenario. A field prediction tends to form a
field-correlated prediction error.
frame
Frame predicted
A typical scenario. A frame prediction tends to form a
frame-correlated prediction error.
field
Frame predicted
Makes little sense. If the encoder went through the
trouble of finding a field prediction in the first place,
why select frame organization for the prediction error?
prediction modes now include field, frame, Dual Prime, and 16x8 MC.
The combinations for Main Profile and Simple Profile are shown below.
Frame pictures
motion_type
motion
vectors
per MB
fundamental
prediction block
size (after half-
pel)
interpretation
Frame
1
16x16
same as MPEG-1, with possibly different
treatment of prediction error via dct_type
Field
2
16x8
Two independently coded predictions are
made: one for the 8 lines which correspond
to the top field, another for the 8 bottom
field lines.
Dual Prime
1
16x8
Two independently coded predictions are
made: one for the 8 lines which correspond
to the top field, another for the 8 bottom
field lines. Uses averaging of two 16x8
prediction blocks from fields of opposite
parity to form a prediction for the top and
bottom 8 lines. A second vector is derived
from the first vector coded in the bitstream.
Field pictures
motion_type
motion
vectors
per MB
fundamental
prediction block
size (after half-
pel)
interpretation
Field
1
16x16
same as MPEG-1, with possibly different
treatment of prediction error via dct_type
16x8
2
16x8
Two independently coded predictions are
made: one for the 8 lines which correspond
to the top field, another for the 8 bottom
field lines.
Dual Prime
1
16x16
A single prediction is constructed from the
average of two 16x16 predictions taken from
fields of opposite parity.
concealment motion vectors can be transmitted in the headers of intra
macroblocks to help error recovery. When the macroblock data that the
concealment motion vectors are intended for becomes corrupt, these
vectors can be used to specify a concealment 16x16 area to be extracted
from the previous picture. These vectors do not affect the normal
decoding process, except for motion vector predictions.
Additional chroma_format for 4:2:2 and 4:4:4 pictures. Like MPEG-1,
Main Profile syntax is strictly limited to 4:2:0 format, however, the
4:2:2 format is the basis of the 4:2:2 Profile (aka Studio Profile).
In 4:2:2 mode, all syntax essentially remains the same except where
matters of block count are concerned. A coded_block_pattern extension
was added to handle signaling of the extra two prediction error
blocks. The 4:4:4 format is currently undefined in any Profile.
chroma_format
multiplex order within Macroblock
Application
4:2:0 (6 blocks)
YYYYCbCr
main stream television, consumer entertainment.
4:2:2 (8 blocks)
YYYYCbCrCbCr
studio production environments, professional
editing equipment, distribution and servers
4:4:4 (12 blocks)
YYYYCbCrCbCrCbCrCbCr
computer graphics
Non-linear macroblock quantization was introduced in MPEG-2 to increase
the precision of quantization at high bit rates, while increasing the
dynamic range for low bit rate use where larger step size is needed.
The quantization_scale_code may be selected between a linear (MPEG-1
style) or non-linear scale on a picture (frame or field) basis. The new
non-linear range corresponds to a dynamic range of 0.5 to 54 with
respect to the linear (MPEG-1 style) range of 1 to 31.
Block:
alternate scan introduced a new run-length entropy scanning pattern
generally more efficient for the statistics of interlaced video
signals. Zig-zag scan is the appropriate choice for progressive
pictures.
intra_dc_precision: the MPEG-1 DC value is mandatory quantized to a
precision of 8 bits. MPEG-2 introduced 9, 10, and 11 bit precision set
on a picture basis to increase the accuracy of the DC component, which
by very nature, has the most significant contribution towards picture
quality. Particularly useful at high bit rates to reduce
posterization. Main and Simple Profiles are limited to 8, 9, or 10 bits
of precision. The 4:2:2 High Profile, which is geared towards higher
bitrate applications (up to 50 Mbits/sec), permits all values (up to 11
bits).
separate quantization matrices for Y and C: luminance (Y) and
chrominance (Cb,Cr) share a common intra and non-intra DCT coefficient
quantization 8x8 matrix in MPEG-1 and MPEG-2 Main and Simple Profiles.
The 4:2:2 Profile permits separate quantization matrices to be
downloaded for the luminance and chrominance blocks. Cb and Cr still
share a common matrix.
intra_vlc_format: one of two tables may now be selected at the picture
layer for variable length codes (VLCs) of AC run-length symbols in
Intra blocks. The first table is identical to that specified for
MPEG-1 (dc_coef_next). The newer second table is more suited to the
statistics of Intra coded blocks, especially in I- frames. The best
illustration between Table 0 and Table 1is the length of the symbol
which represents End of Block (EOB). In Table zero, EOB is 2 bits. In
Table one, it is 4 bits. The implication is that the EOB symbol is
2^-n probable within the block, or from an alternative perspective,
there are an average of 3 to 4 non-zero AC coefficients in Non-intra
blocks, and 9 to 16 coefficients in Intra blocks. The VLC tree of
Table 1 was intended to be a subset of Table 0, to aid hardware
implementations. Both tables have 113 VLC entries (or events).
escape: When no entry in the VLC exists for a AC Run-Level symbol, an
escape code can be used to represent the symbol. Since there are only
63 positions within an 8x8 block following the first coefficient, and
the dynamic range of the quantized DCT coefficients is [-2047,+2048],
there are (63*2047), or 128,961 possible combinations of Run and Level
(the sign bit of the Level follows the VLC). Only the 113 most common
Run-Level symbols are represented in Table 0 or Table 1. The length of
the escape symbol (which is always 6 bits) plus the Run and Level
values in MPEG-1 could be 20 or 28 bits in length. The 20 bit escape
describes levels in the range [-127,+127]. The 28 bit double escape
has a range of [-255, +255]. MPEG-2 increased the span to the full
dynamic range of quantized IDCT coefficients, [-2047, +2047] and
simplified the escape mechanism with a single representation for this
event. The total length of the MPEG-2 escape codeword is 24 bits (6
bit VLC followed by a 6-bit Run value, and 12 bit Level value). It was
an assumption by MPEG-1 designers that no quantized DCT coefficient
would need greater representation than 10 bits [-255,+255]. Note:
MPEG-2 escape mechanism does not permit the value -2048 to be
represented.
mismatch control: The arithmetic results of all stages are defined
exactly by the normative MPEG decoding process, with the single
exception of the Inverse Discrete Cosine Transform (IDCT). This stage
can be implemented with a wide variety of IDCT implementations. Some
are more suited for software, others for programmable hardware, and
others still for hardwired hardware designs. The IDCT reference formula
in the MPEG specification would, if directly implemented, consume at
least 1024 multiply and 1024 addition operations for every block. A
wide variety of fast algorithms exist which can reduce the count to
less than 200 multiplies and 500 adds per block by exploiting the
innate symmetry of the cosine basis functions. A typical fast IDCT
algorithm would be dwarfed by the cost of the other decoder stages
combined. Each fast IDCT algorithm has different quantization error
statistics (fingerprint), although subtle when the precision of the
arithmetic is, for example, at least 16-bits for the transform
coefficients and 24-bits for intermediate dot product values.
Therefore, MPEG cannot standardize a single fast IDCT algorithm. The
accuracy can be defined only statistically. The IEEE 1180
recommendation (December 1990) defines the error tolerance between an
ideal direct-matrix floating point implementation (a direct
implementation of the MPEG reference formula) and the test IDCT.
Mismatch control attempts to reduce the drift between different IDCT
algorithms by eliminating bit patterns which statistically have the
greatest contribution towards mismatches between the variety of
methods. The reconstructions of two decoders will begin to diverge over
time since their respective IDCT designs will reconstruct occasional,
slightly different 8x8 blocks.
MPEG-1s mismatch control method is known canonicially as Oddification,
since it forces all quantized DCT coefficients to negative values. It
is a slight improvement over its predecessor in H.261. MPEG-2 adopted
a different method called, again canonically, LSB Toggling, further
reducing the likelihood of mismatch. Toggling affects only the Least
Significant Bit (LSB) of the 63rd AC DCT coefficient (the highest
frequency in the DCT matrix). Another significant difference between
MPEG-1 and MPEG-2 mismatch control is, in MPEG-1, oddification is
performed on the quantized DCT coefficients, whereas in MPEG-2,
toggling is performed on the DCT coefficients after inverse
quantization. MPEG-1s mismatch control method favors programmable
implementation since a block of DCT coefficients when quantized.
Sample:
The two chrominace pictures (Cb, Cr) possess only half the resolution
in both the horizontal and vertical direction as the luminance picture
(Y). This is the definition of the 4:2:0 chroma format. Most
television displays require that at least the vertical chrominance
resolution matches the luminance (4:2:2 chroma format). Computer
displays may further still demand that the horizontal resolution also
be equivalent (4:4:4 chroma format). There are a variety of filtering
methods for interpolating the chrominance samples to match the sample
density of luminance. However, the official location or center of the
lower resolution chrominance sample should influence the filter design
(relative taps weights), otherwise the chrominance plane can appear to
be shifted by a fractional sample in the wrong direction.
The subsampled MPEG-1 chroma position has a center exactly half way
between the four nearest neighboring luminance samples. To be
consistent with the subsampled chrominance positions of 4:2:2
television signals, MPEG-2 moved the center of the chrominance samples
to be co-located horizontally with the luminance samples.
Misc.:
copyright_id extension can identify whether a sequence or subset of
frames within the sequence is copyrighted, and provides a unique 64-bit
copyright_id_number registered with the ISO/IEC.
Syntax can now signal frame sizes as large as 16383 x 16383. Since
MPEG-1 employed a meager 12-bits to describe horizontal_size and
vertical_size , the range was limited to 4095x4095. However, MPEGs
Levels prescribe important interoperability points for practical
decoders. Constrained Parameters MPEG-1 and MPEG-2 Low Level limit the
sample rate to 352x240x30 Hz. MPEG-2s Main Level defines the limit at
720x480x30 Hz. Of course, this is simply the restriction of the dot
product of horizontal_size, vertical_size, and frame_rate. The Level
also places separate restrictions on each of the these three
variables.
Reflecting the more television oriented manner of MPEG-2, the optional
sequence_display_extension() header can specify the chromaticy of the
source video signal as it was prior to representation by MPEG syntax.
This information includes: whether the original video_format was
composite or component, the opto-electronic transfer_characteristics,
and RGB->YCbCr matrix_coefficients. The picture_display_extension()
provides more localized source composite video characteristics on a
frame by frame basis (not field-by-field), with the syntax elements:
field_sequence, sub_carrier_phase, and burst_amplitude. This
information can be used by the displays post-processing stage to
reproduce a more refined display sequence.
Optional pan & scan syntax was introduced which tells a decoder on a
frame-by-frame basis how to, for example, window a 4:3 image within the
wider 16:9 aspect ratio of the coded frame. The vertical pan offset
can be specified to within 1/16th pixel accuracy.
Part 9 Real-time Interface (RTI): defines a syntax for video on demand
control signals between set-top boxes and head-end servers.
What is the evolution of an MPEG/ISO document?
In chronological order:
Abbr. ISO/Committee notation Author's notation
----- ------------------------------- -----------------------------
- Problem (unofficial first stage) barroom witticism or dare
NI New work Item Napkin Item
NP New Proposal Need Permission
WD Working Draft We�re Drunk
CD Committee Draft Calendar Deadlock
DIS Draft International Standard Doesn't Include Substance
IS International Standard Induced patent Statements
Introductory paper to MPEG?
Didier Le Gall, "MPEG: A Video Compression Standard for Multimedia
Applications," Communications of the ACM, April 1991, Vol.34, No.4, pp.
47-58
MPEG in periodicals?
The following journals and conferences have been known to contain
information relating to MPEG:
IEEE Transactions on Consumer Electronics
IEEE Transactions on Broadcasting
IEEE Transactions on Circuits and Systems for Video Technology
Advanced Electronic Imaging
Electronic Engineering Times (EE Times)
IEEE Int'l Conference on Acoustics, Speech, and Signal Processing (ICASSP)
International Broadcasting Convention (IBC)
Society of Motion Pictures and Television Engineers Journal (SMPTE)
SPIE conference on Visual Communications and Image Processing
MPEG Book?
Several MPEG books are under development.
An MPEG book will be produced by the same team behind the JPEG book:
Joan Mitchell and Bill Pennebaker.... along with Didier Le Gall. It is
expected to be a tutorial on MPEG-1 video and some MPEG-2 video. Van
Nostran Reinhold in 1995.
A book, in the Japanese language, has already been published (ISBN:
4-7561-0247-6). The title is called MPEG by ASCII publishing.
Keith Jack's second edition of Video Demystified, to be published in
August 1995, will feature a large chapter on MPEG video. Information:
ftp://ftp.pub.netcom/pub/kj/kjack/and notity mpeg@powerweb.de via
MPEG is a DCT based scheme?
The DCT and Huffman algorithms receive the most press coverage (e.g.
"MPEG is a DCT based scheme with Huffman coding"), but are in fact less
significant when compared to the variety of coding modes signaled to
the decoder as context-dependent side information. The MPEG-1 and
MPEG-2 IDCT has the same definition as H.261, H.263, JPEG.
What are constant and variable bitrate streams?
Constant bitrate streams are buffer regulated to allow continuos
transfer of coded data across a constant rate channel without causing
an overflow or underflow to a buffer on the receiving end. It is the
responsibility of the Encoders Rate Control stage to generate
bitstreams which prevent buffer overflow and underflow. The constant
bit rate encoding can be modeled as a reservoir: variable sized coded
pictures flow into the bit reservoir, but the reservoir is drained at a
constant rate into the communications channel. The most challenging
aspect of a constant rate encoder is, yes, to maintain constant channel
rate (without overflowing or underflow a buffer of a fixed depth) while
maintaining constant perceptual picture quality.
In the simplest form, variable rate bitstreams do not obey any buffer
rules, but will maintain constant picture quality. Constant picture
quality is easiest to achieve by holding the macroblock quantizer step
size constant (e.g. level 16 of 31). In its most advanced form, a
variable bitrate stream may be more difficult to generate than
constant bitrate streams. In advanced variable bitrate streams, the
instantaneous bit rate (piece-wise bit rate) may be controlled by
factors such as: 1. local activity measured against activity over
large time intervals (e.g. the full span of a movie), or 2.
instantaneous bandwidth availability of a communications channel.
Summary of bitstream types
Bitrate type
Applications
constant-rate
fixed-rate communications channels like the original Compact Disc,
digital video tape, single channel-per-carrier broadcast signal, hard
disk storage
simple variable-rate
software decoders where the bitstream buffer (VBV) is the storage
medium itself (very large). macroblock quantization scale is typically
held constant over large number of macroblocks.
complex variable-rate
Statistical muliplexing (multiple-channel-per-carrier broadcast
signals), compact discs and hard disks where the servo mechanisms can
be controlled to increase or decrease the channel delivery rate,
networked video where overall channel rate is constant but demand is
variably share by multiple users, bitstreams which achieve average
rates over very long time averages
What is statistical multiplexing ?
Progressive explanation:
In the simplest coded bitstream, a PCM (Pulse Coded Modulated) digital
signal, all samples have an equal number of bits. Bit distribution in a
PCM image sequence is therefore not only uniform within a picture,
(bits distributed along zero dimensions), but is also uniform across
the full sequence of pictures.
Audio coding algorithms such as MPEG-1s Layer I and II are capable of
distributing bits over a one dimensional space, spanned by a frame. In
layer II, for example, an audio channel coded at a bitrate of 128
bits/sec and sample rate of 44.1 Khz will have frames (which consist of
1152 subband coefficients each) coded with approximately 334 bits.
Some subbands will receive more bits than others.
In block-based still image compression methods which employ 2-D
transform coding methods, bits are distributed over a 2 dimensional
space (horizontal and vertical) within the block. Further, blocks
throughout the picture may contain a varying number of bits as a
result, for example, of adaptive quantization. For example, background
sky may contain an average of only 50 bits per block, whereas complex
areas containing flowers or text may contain more than 200 bits per
block. In the typical adaptive quantization scheme, more bits are
allocated to perceptually more complex areas in the picture. The
quantization stepsizes can be selected against an overall picture
normalization constant, to achieve a target bit rate for the whole
picture. An encoder which generates coded image sequences comprised of
independently coded still pictures, such as JPEG Motion video or MPEG
Intra picture sequences, will typically generate coded pictures of
equal bit size.
MPEG non-intra coding introduces the concept of the distribution of
bits across multiple pictures, augmenting the distribution space to 3
dimensions. Bits are now allocated to more complex pictures in the
image sequence, normalized by the target bit size of the group of
pictures, while at a lower layer, bits within a picture are still
distributed according to more complex areas within the picture. Yet in
most applications, especially those of the Constant Bitrate class, a
restriction is placed in the encoder which guarantees that after a
period of time, e.g. 0.25 seconds, the coded bitstream achieves a
constant rate (in MPEG, the Video Buffer Verifier regulates the
variable-to-constant rate mapping). The mapping of an inherently
variable bitrate coded signal to a constant rate allows consistent
delivery of the program over a fixed-rate communications channel.
Statistical multiplexing takes the bit distribution model to 4
dimensions: horizontal, vertical, temporal, and program axis. The 4th
dimension is enabled by the practice of mulitplexing multiple programs
(each, for example, with respective video and audio bitstreams) on a
common data carrier. In the Hughes' DSS system, a single data carrier
is modulated with a payload capacity of 23 Mbits/sec, but a typical
program will be transported at average bit rate of 6 Mbit/sec each. In
the 4-D model, bits may be distributed according the relative
complexity of each program against the complexities of the other
programs of the common data carrier. For example, a program undergoing
a rapid scene change will be assigned the highest bit allocation
priority, whereas the program with a near-motionless scene will receive
the lowest priority, or fewest bits.
How does MPEG achieve compression?
Here are some typical statistical conditions addressed by specific
syntax and semantic tools:
1. Spatial correlation: transform coding with 8x8 DCT.
2. Human Visual Response---less acuity for higher spatial frequencies:
lossy scalar quantization of the DCT coefficients.
3. Correlation across wide areas of the picture: prediction of the DC
coefficient in the 8x8 DCT block.
4. Statistically more likely coded bitstream elements/tokens: variable
length coding of macroblock_address_increment, macroblock_type,
coded_block_pattern, motion vector prediction error magnitude, DC
coefficient prediction error magnitude.
5. Quantized blocks with sparse quantized matrix of DCT coefficients:
end_of_block token (variable length symbol).
6. Spatial masking: macroblock quantization scale factor.
7. Local coding adapted to overall picture perception (content
dependent coding): macroblock quantization scale factor.
8. Adaptation to local picture characteristics: block based coding,
macroblock_type, adaptive quantization.
9. Constant stepsizes in adaptive quantization: new quantization scale
factor signaled only by special macroblock_type codes. (adaptive
quantization scale not transmitted by default).
10. Temporal redundancy: forward, backwards macroblock_type and motion
vectors at macroblock (16x16) granularity.
11. Perceptual coding of macroblock temporal prediction error: adaptive
quantization and quantization of DCT transform coefficients (same
mechanism as Intra blocks).
12. Low quantized macroblock prediction error: No prediction error for
the macroblock may be signaled within macroblock_type. This is the
macroblock_pattern switch.
13. Finer granularity coding of macroblock prediction error: Each of
the blocks within a macroblock may be coded or not coded. Selective
on/off coding of each block is achieved with the separate
coded_block_pattern variable-length symbol, which is present in the
macroblock only of the macroblock_pattern switch has been set.
14. Uniform motion vector fields (smooth optical flow fields):
prediction of motion vectors.
15. Occlusion: forwards or backwards temporal prediction in B
pictures. Example: an object becomes temporarily obscured by another
object within an image sequence. As a result, there may be an area of
samples in a previous picture (forward reference/prediction picture)
which has similar energy to a macroblock in the current picture (thus
it is a good prediction), but no areas within a future picture
(backward reference) are similar enough. Therefore only forwards
prediction would be selected by macroblock type of the current
macroblock. Likewise, a good prediction may only be found in a future
picture, but not in the past. In most cases, the object, or
correlation area, will be present in both forward and backward
references. macroblock_type can select the best of the three
combinations.
16. Sub-sample temporal prediction accuracy: bi-linearly interpolated
(filtered) "half-pel" block predictions. Real world motion
displacements of objects (correlation areas) from picture-to-picture do
not fall on integer pel boundaries, but on irrational . Half-pel
interpolation attempts to extract the true object to within one order
of approximation, often improving compression efficiency by at least 1
dB.
17. Limited motion activity in P pictures: skipped macroblocks. When
the motion vector is zero for both the horizontal and vertical vector
components, and no quantized prediction error for the current
macroblock is present. Skipped macroblocks are the most desirable
element in the bitstream since they consume no bits, except for a
slight increase in the bits of the next non-skipped macroblock.
18. Co-planar motion within B pictures: skipped macroblocks. When the
motion vector is the same as the previous macroblocks, and no quantized
prediction error for the current macroblock is present.
What is the difference between MPEG-1 and MPEG-2 syntax?
Section D.9 of ISO/IEC 13818-2 is an informative piece of text
describing the differences between MPEG-1 and MPEG-2 video syntax. The
following is a little more informal.
Sequence layer:
MPEG-2 can represent interlaced or progressive video sequences,
whereas MPEG-1 is strictly meant for progressive sequences since the
target application was Compact Disc video coded at 1.2 Mbit/sec.
MPEG-2 changed the meaning behind the aspect_ratio_information
variable, while significantly reducing the number of defined aspect
ratios in the table. In MPEG-2, aspect_ratio_information refers to the
overall display aspect ratio (e.g. 4:3, 16:9), whereas in MPEG-2, the
ratio refers to the particular pixel. The reduction in the entries of
the aspect ratio table also helps interoperability by limiting the
number of possible modes to a practical set, much like frame_rate_code
limits the number of display frame rates that can be represented.
Optional picture header variables called display_horizontal_size and
display_vertical_size can be used to code unusual display sizes.
frame_rate_code in MPEG-2 refers to the intended display rate, whereas
in MPEG-1 it referred to the coded frame rate. In film source video,
there are often 24 coded frames per second. Prior to bitstream
coding, a good encoder will eliminate the redundant 6 frames or 12
fields from a 30 frame/sec video signal which encapsulates an
inherently 24 frame/sec video source. The MPEG decoder or display
device will then repeat frames or fields to recreate or synthesize the
30 frame/sec display rate. In MPEG-1, the decoder could only infer the
intended frame rate, or derive it based on the Systems layer time
stamps. MPEG-2 provides specific picture header variables called
repeat_first_field and top_field_first which explicitly signal which
frames or fields are to be repeated, and how many times.
To address the concern of software decoders which may operate at rates
lower or different than the common television rates, two new variables
in MPEG-2 called frame_rate_extension_d and frame_rate_extension_n can
be combined with frame_rate_code to specify a much wider variety of
display frame rates. However, in the current set of define profiles
and levels, these two variables are not allowed to change the value
specified by frame_rate_code. Future extensions or Profiles of MPEG
may enable them.
In interlaced sequences, the coded macroblock height (mb_height) of a
picture must be a multiple of 32 pixels, while the width, like MPEG-1,
is a coded multiple of 16 pixels. A discrepancy between the coded
width and height of a picture and the variables horizontal_size and
vertical_size, respectively, occurs when either variable is not an
integer multiple of macroblocks. All pixels must be coded within
macroblocks, since there cannot be such a thing as fractional
macroblocks. Never intended for display, these overhang pixels or
lines exist along the left and bottom edges of the coded picture. The
sample values within these trims can be arbitrary, but they can affect
the values of samples within the current picture, and especially future
coded pictures. In the current pictures, pixels which reside within
the same 8x8 block as the overhang pixels are affect by the ripples of
DCT quantization error. In future coded pictures, their energy can
propagate anywhere within an image sequence as a result of motion
compensated prediction. An encoder should fill in values which are
easy to code, and should probably avoid creating motion vectors which
would cause the Motion Compensated Prediction stage to extract samples
from these areas. The application should probably select
horizontal_size and vertical_size that are already multiples of 16 (or
32 in the vertical case of interlaced sequences) to begin with.
Group of Pictures:
The concept of the Group of Pictures layer does not exist in MPEG-2.
It is an optional header useful only for establishing a SMPTE time code
or for indicating that certain B pictures at the beginning of an edited
sequence comprise a broken_link. This occurs when the current B
picture requires prediction from a forward reference frame (previous in
time to the current picture) has been removed from the bitstream by an
editing process. In MPEG-1, the Group of Pictures header is mandatory,
and must follow a sequence header.
Picture layer:
In MPEG-2, a frame may be coded progressively or interlaced, signaled
by the progressive_frame variable. In interlaced frames
(progressive_frame==0), frames may then be coded as either a frame
picture (picture_structure==frame) or as two separately coded field
pictures (picture_structure==top_field or
picture_structure==bottom_field). Progressive frames are a logic
choice for video material which originated from film, where all pixels
are integrated or captured at the same time instant. Most electronic
cameras today capture pictures in two separate stages: a top field
consisting of all odd lines of the picture are nearly captured in the
time instant, followed by a bottom field of all even lines. Frame
pictures provide the option of coding each macroblock locally as either
field or frame. An encoder may choose field pictures to save memory
storage or reduce the end-to-end encoder-decoder delay by one field
period.
There is no longer such a thing called D pictures in MPEG-2 syntax.
However, Main Profile @ Main Level MPEG-2 decoders, for example, are
still required to decode D pictures at Main Level (e.g. 720x480x30
Hz). The usefulness of D pictures, a concept from the year 1990, had
evaporated by the time MPEG-2 solidified in 1993.
repeat_first_field was introduced in MPEG-2 to signal that a field or
frame from the current frame is to be repeated for purposes of frame
rate conversion (as in the 30 Hz display vs. 24 Hz coded example
above). On average in a 24 frame/sec coded sequence, every other coded
frame would signal the repeat_first_field flag. Thus the 24 frame/sec
(or 48 field/sec) coded sequence would become a 30 frame/sec (60
field/sec) display sequence. This processes has been known for decades
as 3:2 Pulldown. Most movies seen on NTSC displays since the advent of
television have been displayed this way. Only within the past decade
has it become possible to interpolate motion to create 30 truly unique
frames from the original 24. Since the repeat_first_field flag is
independently determined in every frame structured picture, the actual
pattern can be irregular (it doesnt have to be every other frame
literally). An irregularity would occur during a scene cut, for
example.
Slice:
To aid implementations which break the decoding process into parallel
operations along horizontal strips within the same picture, MPEG-2
introduced a general semantic mandatory requirement that all
macroblock rows must start and end with at least one slice. Since a
slice commences with a start code, it can be identified by
inexpensively parsing through the bitstream along byte boundaries.
Before, an implementation might have had to parse all the variable
length tokens between each slice (thereby completing a significant
stage of decoding process in advance) to know the exact position of
each macroblock within the bitstream. In MPEG-1, it was possible to
code a picture with only a single slice. Naturally, the mandatory
slice per macroblock row restriction also facilitates error recovery.
MPEG-2 also added the concept of the slice_id. This optional 6-bit
element signals which picture a particular slice belongs to. In badly
mangled bitstreams, the location of the picture headers could become
garbled. slice_id allows a decoder to place a slice in the proper
location within a sequence. Other elements in the slice header, such
as slice_vertical_position, and the macroblock_address_increment of the
first macroblock in the slice uniquely identify the exact macroblock
position of the slice within the picture. Thus within a window of 64
pictures, a lost slice can find its way.
Macroblock:
motion vectors are now always represented along a half-pel grid. The
usefulness of an integer-pel grid (option in MPEG-1) diminished with
practice. A intrinsic half-pel accuracy can encourage use by encoders
for the significant coding gain which half-pel interpolation offers.
In both MPEG-1 and MPEG-2, the dynamic range of motion vectors is
specified on a picture basis. A set of pictures corresponding to a
rapid motion scene may need a motion vector range of up to +/- 64
integer pixels. A slower moving interval of pictures may need only a
+/- 16 range. Due to the syntax by which motion vectors are signaled in
a bitstream, pictures with little motion would suffer unnecessary bit
overhead in describing motion vectors in a coordinate system
established for a much wider range. MPEG-1s f_code picture header
element prescribed a radius shared by horizontal and vertical motion
vector components alike. It later became practice in industry to have a
greater horizontal search range (motion vector radius) than vertical,
since motion tends to be more prominent across the screen than up or
down (vertical). Secondly, a decoder has a limited frame buffer size
in which to store both the current picture under decoding and the set
of pictures (forward, backward) used for prediction (reference) by
subsequent pictures. A decoder can write over the pixels of the oldest
reference picture as soon as it no longer is needed by subsequent
pictures for prediction. A restricted vertical motion vector range
creates a sliding window, which starts at the top of the reference
picture and moves down as the macroblocks in the current picture are
decoded in raster order. The moment a strip of pixels passes outside
this window, they have ended their life in the MPEG decoding loop. As
a result of all this, MPEG-2 created separate into horizontal and
vertical range specifiers (f_code[][0] for horizontal, and f_code[][1]
for vertical), and placed greater restrictions on the maximum vertical
range than on the horizontal range. In Main Level frame pictures, this
is range is [- 128,+127.5] vertically, and [-1024,+1023.5]
horizontally. In field pictures, the vertical range is restricted to [-
64,+63.5].
Macroblock stuffing is now illegal in MPEG-2. The original intent
behind stuffing in MPEG-1 was to provide a means for finer rate control
adjustment at the macroblock layer. Since no self-respecting encoder
would waste bits on such an element (it does not contribute to the
refinement of the reconstructed video signal), and since this unlimited
loop of stuffing variable length codes represent a significant headache
for hardware implementations which have a fixed window of time in which
to parse and decode a macroblock in a pipeline, the element was
eliminated in January 1993 from the MPEG-2 syntax. Some feel that
macroblock stuffing was beneficial since it permitted macroblocks to be
coded along byte boundaries. A good compromise could have been a
limited number of stuffs per macroblock. If stuffing is needed for
purposes of rate control, an encoder can pad extra zero bytes before
the start code of the next slice. If stuffing is required in the last
row of macroblocks of the picture, the picture start code of the next
picture can be padded with an arbitrary number of bytes. If the
picture happens to be the last in the sequence, the sequence_end_code
can be stuffed with zero bytes.
The dct_type flag in both Intra and non-Intra coded macroblocks of
frame structured pictures signals that the reconstructed samples output
by the IDCT stage shall be organized in field or frame order. This
flag provides an encoder with a sort of poor mans motion_type by
adapting to the interparity (i.e. interfield) characteristics of the
macroblock without signaling a need for motion vectors via the
macroblock_type variable. dct_type plays an essential role in Intra
frame pictures by organizing lines of a common parity together when
there is significant interfield motion within the macroblock. This
increases the decorrelation efficiency of the DCT stage. For
non-intra macroblocks, dct_type organizes the 16 lines (... luminance,
8 lines chrominance) of the macroblock prediction error. In combination
with motion_type, the meaning....
dct_type
motion_format
interpretation
frame
Intra coded
block data is frame correlated
field
Intra coded
block data is more strongly correlated along lines of
opposite parity
frame
Field predicted
1. a low-cost encoder which only possesses frame
motion estimation may use dct_type to decorrelate
the prediction error of a prediction which is
inherently field by characteristic
2. an intelligent encoder realizes that it is more bit
efficient to signal frame prediction with field
dct_type for the prediction error, than it is to signal
a field prediction.
field
Field predicted
A typical scenario. A field prediction tends to form a
field-correlated prediction error.
frame
Frame predicted
A typical scenario. A frame prediction tends to form a
frame-correlated prediction error.
field
Frame predicted
Makes little sense. If the encoder went through the
trouble of finding a field prediction in the first place,
why select frame organization for the prediction error?
prediction modes now include field, frame, Dual Prime, and 16x8 MC.
The combinations for Main Profile and Simple Profile are shown below.
Frame pictures
motion_type
motion
vectors
per MB
fundamental
prediction block
size (after half-
pel)
interpretation
Frame
1
16x16
same as MPEG-1, with possibly different
treatment of prediction error via dct_type
Field
2
16x8
Two independently coded predictions are
made: one for the 8 lines which correspond
to the top field, another for the 8 bottom
field lines.
Dual Prime
1
16x8
Two independently coded predictions are
made: one for the 8 lines which correspond
to the top field, another for the 8 bottom
field lines. Uses averaging of two 16x8
prediction blocks from fields of opposite
parity to form a prediction for the top and
bottom 8 lines. A second vector is derived
from the first vector coded in the bitstream.
Field pictures
motion_type
motion
vectors
per MB
fundamental
prediction block
size (after half-
pel)
interpretation
Field
1
16x16
same as MPEG-1, with possibly different
treatment of prediction error via dct_type
16x8
2
16x8
Two independently coded predictions are
made: one for the 8 lines which correspond
to the top field, another for the 8 bottom
field lines.
Dual Prime
1
16x16
A single prediction is constructed from the
average of two 16x16 predictions taken from
fields of opposite parity.
concealment motion vectors can be transmitted in the headers of intra
macroblocks to help error recovery. When the macroblock data that the
concealment motion vectors are intended for becomes corrupt, these
vectors can be used to specify a concealment 16x16 area to be extracted
from the previous picture. These vectors do not affect the normal
decoding process, except for motion vector predictions.
Additional chroma_format for 4:2:2 and 4:4:4 pictures. Like MPEG-1,
Main Profile syntax is strictly limited to 4:2:0 format, however, the
4:2:2 format is the basis of the 4:2:2 Profile (aka Studio Profile).
In 4:2:2 mode, all syntax essentially remains the same except where
matters of block count are concerned. A coded_block_pattern extension
was added to handle signaling of the extra two prediction error
blocks. The 4:4:4 format is currently undefined in any Profile.
chroma_format
multiplex order within Macroblock
Application
4:2:0 (6 blocks)
YYYYCbCr
main stream television, consumer entertainment.
4:2:2 (8 blocks)
YYYYCbCrCbCr
studio production environments, professional
editing equipment, distribution and servers
4:4:4 (12 blocks)
YYYYCbCrCbCrCbCrCbCr
computer graphics
Non-linear macroblock quantization was introduced in MPEG-2 to increase
the precision of quantization at high bit rates, while increasing the
dynamic range for low bit rate use where larger step size is needed.
The quantization_scale_code may be selected between a linear (MPEG-1
style) or non-linear scale on a picture (frame or field) basis. The new
non-linear range corresponds to a dynamic range of 0.5 to 54 with
respect to the linear (MPEG-1 style) range of 1 to 31.
Block:
alternate scan introduced a new run-length entropy scanning pattern
generally more efficient for the statistics of interlaced video
signals. Zig-zag scan is the appropriate choice for progressive
pictures.
intra_dc_precision: the MPEG-1 DC value is mandatory quantized to a
precision of 8 bits. MPEG-2 introduced 9, 10, and 11 bit precision set
on a picture basis to increase the accuracy of the DC component, which
by very nature, has the most significant contribution towards picture
quality. Particularly useful at high bit rates to reduce
posterization. Main and Simple Profiles are limited to 8, 9, or 10 bits
of precision. The 4:2:2 High Profile, which is geared towards higher
bitrate applications (up to 50 Mbits/sec), permits all values (up to 11
bits).
separate quantization matrices for Y and C: luminance (Y) and
chrominance (Cb,Cr) share a common intra and non-intra DCT coefficient
quantization 8x8 matrix in MPEG-1 and MPEG-2 Main and Simple Profiles.
The 4:2:2 Profile permits separate quantization matrices to be
downloaded for the luminance and chrominance blocks. Cb and Cr still
share a common matrix.
intra_vlc_format: one of two tables may now be selected at the picture
layer for variable length codes (VLCs) of AC run-length symbols in
Intra blocks. The first table is identical to that specified for
MPEG-1 (dc_coef_next). The newer second table is more suited to the
statistics of Intra coded blocks, especially in I- frames. The best
illustration between Table 0 and Table 1is the length of the symbol
which represents End of Block (EOB). In Table zero, EOB is 2 bits. In
Table one, it is 4 bits. The implication is that the EOB symbol is
2^-n probable within the block, or from an alternative perspective,
there are an average of 3 to 4 non-zero AC coefficients in Non-intra
blocks, and 9 to 16 coefficients in Intra blocks. The VLC tree of
Table 1 was intended to be a subset of Table 0, to aid hardware
implementations. Both tables have 113 VLC entries (or events).
escape: When no entry in the VLC exists for a AC Run-Level symbol, an
escape code can be used to represent the symbol. Since there are only
63 positions within an 8x8 block following the first coefficient, and
the dynamic range of the quantized DCT coefficients is [-2047,+2048],
there are (63*2047), or 128,961 possible combinations of Run and Level
(the sign bit of the Level follows the VLC). Only the 113 most common
Run-Level symbols are represented in Table 0 or Table 1. The length of
the escape symbol (which is always 6 bits) plus the Run and Level
values in MPEG-1 could be 20 or 28 bits in length. The 20 bit escape
describes levels in the range [-127,+127]. The 28 bit double escape
has a range of [-255, +255]. MPEG-2 increased the span to the full
dynamic range of quantized IDCT coefficients, [-2047, +2047] and
simplified the escape mechanism with a single representation for this
event. The total length of the MPEG-2 escape codeword is 24 bits (6
bit VLC followed by a 6-bit Run value, and 12 bit Level value). It was
an assumption by MPEG-1 designers that no quantized DCT coefficient
would need greater representation than 10 bits [-255,+255]. Note:
MPEG-2 escape mechanism does not permit the value -2048 to be
represented.
mismatch control: The arithmetic results of all stages are defined
exactly by the normative MPEG decoding process, with the single
exception of the Inverse Discrete Cosine Transform (IDCT). This stage
can be implemented with a wide variety of IDCT implementations. Some
are more suited for software, others for programmable hardware, and
others still for hardwired hardware designs. The IDCT reference formula
in the MPEG specification would, if directly implemented, consume at
least 1024 multiply and 1024 addition operations for every block. A
wide variety of fast algorithms exist which can reduce the count to
less than 200 multiplies and 500 adds per block by exploiting the
innate symmetry of the cosine basis functions. A typical fast IDCT
algorithm would be dwarfed by the cost of the other decoder stages
combined. Each fast IDCT algorithm has different quantization error
statistics (fingerprint), although subtle when the precision of the
arithmetic is, for example, at least 16-bits for the transform
coefficients and 24-bits for intermediate dot product values.
Therefore, MPEG cannot standardize a single fast IDCT algorithm. The
accuracy can be defined only statistically. The IEEE 1180
recommendation (December 1990) defines the error tolerance between an
ideal direct-matrix floating point implementation (a direct
implementation of the MPEG reference formula) and the test IDCT.
Mismatch control attempts to reduce the drift between different IDCT
algorithms by eliminating bit patterns which statistically have the
greatest contribution towards mismatches between the variety of
methods. The reconstructions of two decoders will begin to diverge over
time since their respective IDCT designs will reconstruct occasional,
slightly different 8x8 blocks.
MPEG-1s mismatch control method is known canonicially as Oddification,
since it forces all quantized DCT coefficients to negative values. It
is a slight improvement over its predecessor in H.261. MPEG-2 adopted
a different method called, again canonically, LSB Toggling, further
reducing the likelihood of mismatch. Toggling affects only the Least
Significant Bit (LSB) of the 63rd AC DCT coefficient (the highest
frequency in the DCT matrix). Another significant difference between
MPEG-1 and MPEG-2 mismatch control is, in MPEG-1, oddification is
performed on the quantized DCT coefficients, whereas in MPEG-2,
toggling is performed on the DCT coefficients after inverse
quantization. MPEG-1s mismatch control method favors programmable
implementation since a block of DCT coefficients when quantized.
Sample:
The two chrominace pictures (Cb, Cr) possess only half the resolution
in both the horizontal and vertical direction as the luminance picture
(Y). This is the definition of the 4:2:0 chroma format. Most
television displays require that at least the vertical chrominance
resolution matches the luminance (4:2:2 chroma format). Computer
displays may further still demand that the horizontal resolution also
be equivalent (4:4:4 chroma format). There are a variety of filtering
methods for interpolating the chrominance samples to match the sample
density of luminance. However, the official location or center of the
lower resolution chrominance sample should influence the filter design
(relative taps weights), otherwise the chrominance plane can appear to
be shifted by a fractional sample in the wrong direction.
The subsampled MPEG-1 chroma position has a center exactly half way
between the four nearest neighboring luminance samples. To be
consistent with the subsampled chrominance positions of 4:2:2
television signals, MPEG-2 moved the center of the chrominance samples
to be co-located horizontally with the luminance samples.
Misc.:
copyright_id extension can identify whether a sequence or subset of
frames within the sequence is copyrighted, and provides a unique 64-bit
copyright_id_number registered with the ISO/IEC.
Syntax can now signal frame sizes as large as 16383 x 16383. Since
MPEG-1 employed a meager 12-bits to describe horizontal_size and
vertical_size , the range was limited to 4095x4095. However, MPEGs
Levels prescribe important interoperability points for practical
decoders. Constrained Parameters MPEG-1 and MPEG-2 Low Level limit the
sample rate to 352x240x30 Hz. MPEG-2s Main Level defines the limit at
720x480x30 Hz. Of course, this is simply the restriction of the dot
product of horizontal_size, vertical_size, and frame_rate. The Level
also places separate restrictions on each of the these three
variables.
Reflecting the more television oriented manner of MPEG-2, the optional
sequence_display_extension() header can specify the chromaticy of the
source video signal as it was prior to representation by MPEG syntax.
This information includes: whether the original video_format was
composite or component, the opto-electronic transfer_characteristics,
and RGB->YCbCr matrix_coefficients. The picture_display_extension()
provides more localized source composite video characteristics on a
frame by frame basis (not field-by-field), with the syntax elements:
field_sequence, sub_carrier_phase, and burst_amplitude. This
information can be used by the displays post-processing stage to
reproduce a more refined display sequence.
Optional pan & scan syntax was introduced which tells a decoder on a
frame-by-frame basis how to, for example, window a 4:3 image within the
wider 16:9 aspect ratio of the coded frame. The vertical pan offset
can be specified to within 1/16th pixel accuracy.
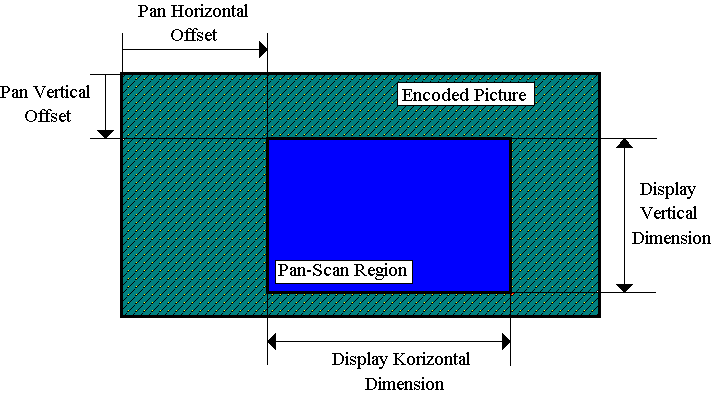 How does MPEG syntax facilitate parallelism ?
For MPEG-1, slices may consist of an arbitrary number of macroblocks.
They can be independently decoded once the picture header side
information is known. For parallelism below the slice level, the coded
bitstream must first be mapped into fixed-length elements. Further,
since macroblocks have coding dependencies on previous macroblocks
within the same slice, the data hierarchy must be pre-processed down to
the layer of DC DCT coefficients. After this, blocks may be
independently inverse transformed and quantized, temporally predicted,
and reconstructed to buffer memory. Parallelism is usually more of a
concern for encoders. In many encoders today, block matching (motion
estimation) and some rate control stages (such as activity and/or
complexity measures) are processed for macroblocks independently.
Finally, with the exception that all macroblock rows in Main Profile
MPEG-2 bitstreams must contain at least one slice, an encoder has the
freedom to choose the slice structure.
What is the MPEG color space and sample precision?
MPEG strictly specifies the YCbCr color space, not YUV or YIQ or YPbPr
or YDrDb or any other many fine varieties of color difference spaces.
Regardless of any bitstream parameters, MPEG-1 and MPEG-2 Video Main
Profile specify the 4:2:0 chroma_format, where the color difference
channels (Cb, Cr) have half the "resolution" or sample grid density in
both the horizontal and vertical direction with respect to luminance.
MPEG-2 High Profile includes an option for 4:2:2 chroma_format, as does
the MPEG 4:2:2 Profile (a.k.a. Studio Profile) naturally. Applications
for the 4:2:2 format can be found in professional broadcasting,
editing, and contribution-quality distribution environments. The
drawback of the 4:2:2 format is simply that it increases the size of
the macroblock from six 8x8 blocks (4:2:0) to eight, while increasing
the frame buffer size and decoding bandwidth by the same amount (33
%). This increase places the buffering memories well past the magic
16-Mbit limit for semiconductor DRAM devices, assuming the pictures are
stored with a maximum of 414,720 pixels (720 pixels/line x 576
lines/frame). The maximum allowable pixel resolution could be reduced
by 1/3 to compensate (e.g. 544 x 576). However, if a hardware decoders
operate on a macroblock basis in the pipeline, on-chip static memories
(SRAM) will increase by 1/3. The benefits offered by 1/3 more pixels
generally outweighs full vertical chrominance resolution. Other
arguments favoring 4:2:0 over 4:2:2 include:
Vertical decimation increases compression efficiency by reducing
syntax overhead posed in an 8 block (4:2:2) macroblock structure.
You're compressing the hell out of the video signal, so what possible
difference can the 0:0:2 chromiance high-pass make?
Is 4:2:0 the same as 4:1:1 ?
No, no, definitely no. The following table illustrates the nuances
between the different chroma formats for a frame with pixel dimensions
of 720 pixels/line x 480 lines/frame.
CCIR 601 (60 Hz) image Chroma sub-sampling factors
format Y Cb, Cr Vertical Horizontal
chroma
format
pixels/
line
Y
lines/
frame
Y
pixels/
line
Cb, Cr
lines/
frame
Cb, Cr
horizontal
subsampling
factor
vertical
subsampling
factor
4:4:4
720
480
720
480
none
none
4:2:2
720
480
360
480
2:1
none
4:2:0
720
480
360
240
2:1
2:1
4:1:1
720
480
180
480
4:1
none
4:1:0
720
480
180
120
4:1
4:1
3:2:2, 3:1:1, and 3:1:0 are less common variations, but have been
documented. As shocking as it may seem, the 4:1:0 ratio was used by
Intels DVI for several years.
The 130 microsecond gap between successive 4:2:0 lines in progressive
frames, and 260 microsecond gap in interlaced frames, can introduce
some difficult vertical frequencies, but most can be alleviated through
pre- processing.
What is the sample precision of MPEG ? How many colors
can MPEG represent ?
By definition, MPEG samples have no more and no less than 8-bits
uniform sample precision (256 quantization levels). For luminance
(which is unsigned) data, black corresponds to level 0, white is level
255. However, in CCIR recommendation 601 chromaticy, luminance (Y)
levels 0 through 14 and 236 through 255 are reserved for blanking
signal excursions. MPEG currently has no such clipped excursion
restrictions, although decoder might take care to insure active samples
do not exceed these limits. With three color components per pixel, the
total combination is roughly 16.8 million colors (i.e. 24-bits).
How are the subsampled chroma samples cited ?
It is moderately important to properly co-site chroma samples,
otherwise a sort of chroma shifting effect (exhibited as a halo) may
result when the reconstructed video is displayed. In MPEG-1 video, the
chroma samples are exactly centered between the 4 luminance samples
(Fig 1.) To maintain compatibility with the CCIR 601 horizontal
chroma locations and simplify implementation (eliminate need for phase
shift), MPEG-2 chroma samples are arranged as per Fig.2.
Y Y Y Y Y Y Y Y YC Y YC Y
C C C C
Y Y X Y Y Y Y Y YC Y YC Y
Y Y Y Y Y Y Y Y YC Y YC Y
C C C C
Y Y Y Y Y Y Y Y YC Y YC Y
Fig.1 MPEG-1 Fig.2 MPEG-2 Fig.3 MPEG-2 and
4:2:0 organization 4:2:0 organization CCIR Rec. 601
4:2:2 organization
How do you tell an MPEG-1 bitstream from an MPEG-2
bitstream ?
A. All MPEG-2 bitstreams must contain specific extension headers that
immediately follow MPEG-1 headers. At the highest layer, for example,
the MPEG-1 style sequence_header() is followed by sequence_extension().
Some extension headers are specific to MPEG-2 profiles. For example,
sequence_scalable_extension() is not allowed in Main Profile
bitstreams.
A simple program need only scan the coded bitstream for byte-aligned
start codes to determine whether the stream is MPEG-1 or MPEG-2.
What are start codes?
These 32-bit byte-aligned codes provide a mechanism for cheaply
searching coded bitstreams for commencement of various layers of video
without having to actually parse variable-length codes or perform any
decoder arithmetic. Start codes also provide a mechanism for
resynchronization in the presence of bit errors. A start code may be
preceded by an arbitrary number of zero bytes. The zero bytes can be
use to guarantee that a start code occurs within a certain location, or
by rate control to increase the bitrate of a coded bitstream.
Coded block pattern
Coded block pattern:
(CBP --not to be confused with Constrained Parameters!) When the frame
prediction is particularly good, the displaced frame difference(DFD, or
temporal macroblock prediction error) tends to be small, often with
entire block energy being reduced to zero after quantization. This
usually happens only at low bit rates. Coded block patterns prevent
the need for transmitting EOB symbols in those zero coded blocks.
Coded block patterns are transmitted in the macroblock header only if
the macrobock_type flag indicates so.
Why is the DC value always divided by 8 ?
Clarification point: The DC value of Intra coded blocks is quantized by
a constant stepsize of 8 only in MPEG-1, rendering the 11-bit dynamic
range of the IDCT DC coefficient to 8-bits of accuracy. MPEG-2 allows
for DC precision of 8, 9, 10, or 11 bits. The quantization stepsize is
fixed for the duration of the picture, set by the intra_dc_precision
flag in the picture_extension_header().
Why is there a special VLC for DCT_coefficient_first:?
Since the coded_block_pattern in NON-INTRA macroblocks signals every
possible combination of all-zero valued and non-zero blocks, the
dct_coef_first mechanism assigns a different meaning to the VLC
codeword (run = 0, level =+/- 1) that would otherwise represent EOB
(10) as the first coefficient in the zig-zag ordered Run-Level token
list.
What�s the deal with End of Block ?
Saves unnecessary run-length codes. At optimal bitrates, there tends
to be few AC coefficients concentrated in the early stages of the
zig-zag vector. In MPEG-1, the 2-bit length of EOB implies that there
is an average of only 3 or 4 non-zero AC coefficients per block. In
MPEG-2 Intra (I) pictures, with a 4-bit EOB code in Table 1, this
estimate is between 9 and 16 coefficients. Since EOB is required for
all coded blocks, its absence can signal that a syntax error has
occurred in the bitstream.
What�s this �Macroblock stuffing,� dammit ?:
A genuine pain for VLSI implementations, macroblock stuffing was
included in MPEG-1 to maintain smoother, constant bitrate control for
encoders. However, with normalized complexity/activity measures and
buffer management performed a priori (before coding of the macroblock,
for example) and local monitoring of coded data buffer levels now a
common operation in encoders, (e.g. MPEG-2 encoder Test Model), the
need for such localized bitrate smoothing evaporated. Stuffing can be
achieved through slice start code padding if required. A good rule of
thumb is: if you find often yourself wishing for stuffing more than
once per slice, you probably don't have a very good rate control
algorithm. Nonetheless, to avoid any temptation, macroblock stuffing
is now illegal in MPEG-2 (A general syntax restriction brought to you
by the Implementation Studies Subgroup!)
What�s the deal with slice_vertical_position and
macroblock_address_increment?
The absolute position of the first macroblock within a slice is known
by the combination of slice_vertical_position and the
macroblock_address_increment. Therefore, the proper place of a lost
slice found in a highly corrupt bitstream can be located exactly within
the picture. These two syntax elements are also the only known means
of detecting slice gaps----areas of the picture which are not
represented with any information (including skipped macroblocks). A
slice gap occurs when the current macroblock address of the first
macroblock in a slice is greater than the previous macroblock address
by more than 1 macroblock unit. A slice overlap occurs when the current
macroblock address is less than or equal to the previous macroblocks
address. The previous macroblock in both instances is the last known
macroblock within the previous slice. Because of the semantic
interpretation of slice gaps and overlaps, and because of the syntactic
restrictions for slice_vertical_position and
macroblock_address_increment, it is not syntactically possible for a
skipped macroblock to be represented in the first and last positions of
a slice. In the past, some (bad) encoders would attempt to signal a
run of skipped macroblocks to the end of the slice. These evil skipped
macroblocks should be interpreted by a compliant decoder as a gap, not
as a string of skipped macroblocks.
What is meant by modified Huffman VLC tables:
The VLC tables in MPEG are not Huffman tables in the true sense of
Huffman coding, but are more like the tables used in Group 3 fax. They
are entropy constrained, that is, non-downloadable and optimized for a
limited range of bit rates (sweet spots). A better way would be to say
that the tables are optimized for a range of ratios of bit rate to
sample rate (e.g. 0.25 bits/pixel to 1.0 bits/pixel). With the
exception of a few codewords, the larger tables were carried over from
the H.261 standard drafted in the year 1990. This includes the AC
run-level symbols, coded_block_pattern, and macroblock_address_increment.
MPEG-2 added an "Intra table," also called "Table 1". Note that the
dct_coefficient tables assume positive/negative coefficient PMF
symmetry.
How does MPEG handle 3:2 pulldown?
MPEG-1 video decoders had to decide for themselves when to perform 3:2
pulldown if it was not indicated in the presentation time stamps (PTS)
of the Systems layer bitstream. MPEG-2 provides two flags
(repeat_first_field, and top_field_first) which explicitly describe
whether a frame or field is to be repeated. In progressive sequences,
frames can be repeated 2 or 3 times. Simple and Main Profile limit are
limited to repeated fields only. It is a general syntactic restriction
that repeat_first_field can only be signaled (value ==1) in a frame
structured picture. It makes little sense to repeat field pictures in
an interlaced video signal since the whole process of 3:2 pulldown
conversion was meant to convert progressive, film sequences to the
display frame rate of interlaced television.
In the most common scenario, a film sequence will contain 24 frames
every second. The bit_rate element in the sequence header will
indicate 30 frames/sec, however. On average, every other coded frame
will signal a repeat field (repeat_first_field==1) to pad the frame
rate from 24 Hz to 30 Hz:
(24 coded frames/sec)*(2 fields/coded frame)*(5 display fields/4 coded
fields) = 30 display frames/sec
After all this standardization, what�s left for research?
A . Despite the fact that a comprehensive worldwide standard now exists
for digital video, many areas remain wide open for research: advanced
encoding and pre-processing, motion estimation, macroblock decision
models, rate control and buffer management in editing environments,
implementation complexity reduction, etc. Many areas have yet to be
solved ... (and discovered)..
Are some encoders better than others ?
A. Definitely. For example, the motion estimation search range of a
has great influence over final picture quality. At a certain point a
very large range can actually become detrimental (it may encourage
large differential motion vectors). Practical ranges are usually
between +/- 15 and +/- 32. As the range doubles, for instance, the
search area quadruples. (like the classic relationship between in
increase in linear vs. area).
Rate control marks a second tell-tale area where some encoders perform
significantly better than others.
And finally, the degree of "pre-processing" (now a popular buzzword in
the business) signals that the encoder belongs to an elite marketing
class.
Is the encoder standardized ?
A. The encoder rests just outside the normative scope of the standard,
as long as the bitstreams it produces are compliant. The decoder,
however, is almost deterministic: a given bitstream should reconstruct
to a unique set of pictures. However, since the IDCT function is the
ONLY non-normative stage in the decoder, an occasional error of a Least
Significant Bit per prediction iteration is permitted. The designer is
free to choose among many DCT algorithms and implementations. The IEEE
1180 test referenced in Annex A of the MPEG-1 (ISO/IEC 11172-2) and
MPEG-2 (ISO/IEC 13818-2) Video specifications spells out the
statistical mismatch tolerance between the Reference IDCT, which is a
separable 8x1 "Direct Matrix" DCT implemented with 64-bit floating
point accuracy, and the IDCT you are testing for compliance.
What is the TM (Test Model) ?
What is the TM rate control and adaptive quantization technique ?
A. The Test model (MPEG-2) and Simulation Model (MPEG-1) were not, by
any stretch of the imagination, meant to epitomize state-of-the art
encoding quality. They were, however, designed to exercise the syntax,
verify proposals, and test the relative compression performance of
proposals in a timely manner that could be duplicated by
co-experimenters. Without simplicity, there would have been no doubt
endless debates over model interpretation. Regardless of all else,
more advanced techniques would probably trespass into proprietary
territory.
The final test model for MPEG-2 is TM version 5b, a.k.a. TM version 6,
produced in March 1993 (the time when the MPEG-2 video syntax was
frozen). The final MPEG-1 simulation model is version 3 (SM-3). The
MPEG-2 TM rate control method offers a dramatic improvement over the SM
method. TM adds more accurate estimation of macroblock complexity
through use of limited a priori information. Macroblock quantization
adjustments are computed on a macroblock basis, instead of
once-per-macroblock row (which in the SM-3 case consisted of an entire
slice).
How does the TM work?
Rate control and adaptive quantization are divided into three steps:
Step One: Target Bit Allocation
In Complexity Estimation, the global complexity measures assign
relative weights to each picture type (I,P,B). These weights (Xi, Xp,
Xb) are reflected by the typical coded frame size of I, P, and B
pictures (see typical frame size discussion). I pictures are usually
assigned the largest weight since they have the greatest stability
factor in an image sequence and contain the most new information in a
sequence. B pictures are assigned the smallest weight since B energy
do not propagate into other pictures and are usually more highly
correlated with neighboring P and I pictures than P pictures are.
The bit target for a frame is based on the frame type, the remaining
number of bits left in the Group of Pictures (GOP) allocation, and the
immediate statistical history of previously coded pictures (sort of a
moving average global rate control, if you will).
Step Two: Rate Control via Buffer Monitoring
Rate control attempts to adjust bit allocation if there is significant
difference between the target bits (anticipated bits) and actual coded
bits for a block of data. If the virtual buffer begins to overflow,
the macroblock quantization step size is increased, resulting in a
smaller yield of coded bits in subsequent macroblocks. Likewise, if
underflow begins, the step size is decreased. The Test Model
approximates that the target picture has spatially uniform distribution
of bits. This is a safe approximation since spatial activity and
perceived quantization noise are almost inversely proportional. Of
course, the user is free to design a custom distribution, perhaps
targeting more bits in areas that contain more complex yet highly
perceptible data such as text.
Step Three: Adaptive Quantization
The final step modulates the macroblock quantization step size obtained
in Step 2 by a local activity measure. The activity measure itself is
normalized against the most recently coded picture of the same type (I,
P, or B). The activity for a macroblock is chosen as the minimum among
the four 8x8 block luminance variances. Choosing the minimum block is
part of the concept that a macroblock is no better than the block of
highest visible distortion (weakest link in the chain).
Decision:
[deferred to later date]
Can motion vectors be used to determine object velocity?
Motion vector information cannot be reliably used as a means of
determining object velocity unless the encoder model specifically set
out to do so. First, encoder models that optimize picture quality
generate vectors that typically minimize prediction error and,
consequently, the vectors often do not represent true object
translation from picture-to-picture. Standards converters that
resample one frame rate to another (as in NTSC to PAL) use different
methods (motion vector field estimation, edge detection, et al) that
are not concerned with Rate-Distortion theory. Second, motion vectors
are not transmitted for all macroblocks anyway.
Is it possible to code interlaced video with MPEG-1 syntax?
A. Two methods can be applied to interlaced video that maintain
syntactic compatibility with MPEG-1 (which was originally designed for
progressive frames only). In the field concatenation method, the
encoder model can carefully construct predictions and prediction errors
that realize good compression but maintain field integrity (distinction
between adjacent fields of opposite parity). Some pre-processing
techniques can also be applied to the interlaced source video that
would, e.g., lessen sharp vertical frequencies.
This technique is not terribly efficient of course. On the other hand,
if the original source was progressive (e.g. film), then it is more
trivial to convert the interlaced source to a progressive format before
encoding. (MPEG-2 would then only offer slightly superior performance
through such MPEG-2 enhancements as greater DC coefficient precision,
non-linear mquant, intra VLC, etc.) Reconstructed frames are usually
re- interlaced in the Display process following the decoding stages.
The second syntactically compatible method codes fields as separate
pictures. Rumors have spread that this approach does not quiet work
nearly as well as the pretend its really a frame method.
Can MPEG be used to code still frames ?
Yes. MPEG Intra pictures are similar to baseline sequential JPEG pictures.
There are, of course, advantages and disadvantages to using MPEG over
JPEG to represent still pictures.
Disadvantages:
1. MPEG has only one color space (YCbCr)
2. MPEG-1 and MPEG-2 Main Profile luma and chroma share quanitzation
and VLC tables (4:2:0 chroma_format)
3. MPEG-1 is syntactically limited to 4k x 4k images, and 16k x 16k for MPEG-2.
Advantages:
1. MPEG possesses adaptive quantization which permits better rate
control and spatial masking.
2. With its limited still image syntax, MPEG averts any temptation to
use unnecessary, expensive, and academic encoding methods that have
little impact on the overall picture quality (you know who you are).
3. Philips' CD-I spec. has a requirement for a MPEG still frame mode,
with double SIF image resolution. This is technically feasible mostly
thanks to the fact that only one picture buffer is needed to decode a
still image instead of the 2.5 to 3 buffers needed for IPB sequences.
Why was the 8x8 DCT size chosen?
A. Experiments showed little compaction gains could be achieved with
larger transform sizes, especially in light of the increased
implementation complexity. A fast DCT algorithm will require roughly
double the number of arithmetic operations per sample when the linear
transform point size is doubled. Naturally, the best compaction
efficiency has been demonstrated using locally adaptive block sizes
(e.g. 16x16, 16x8, 8x8, 8x4, and 4x4) [See Gary Sullivan and Rich
Baker "Efficient Quadtree Coding of Images and Video," ICASSP 91, pp
2661-2664.].
Inevitably, adaptive block transformation sizes introduce additional
side information overhead while forcing the decoder to implement
programmable or hardwired recursive DCT algorithms. If the DCT size
becomes too large, then more edges (local discontinuities) and the like
become absorbed into the transform block, resulting in wider
propagation of Gibbs (ringing) and other unpleasant phenomena.
Finally, with larger transform sizes, the DC term is even more
critically sensitive to quantization noise.
Why was the 16x16 prediction size chosen?
The 16x16 area corresponds to the Least Common Multiple (LCM) of 8x8
blocks, given the normative 4:2:0 chroma ratio. Starting with medium
size images, the 16x16 area provides a good balance between side
information overhead & complexity and motion compensated prediction
accuracy. In gist, experiments showed that the 16x16 was a good
trade-off between complexity and coding efficiency.
What do B-pictures buy you?
A. Since bi-directional macroblock predictions are an average of two
macroblock areas, noise is reduced at low bit rates (like a 3-D filter,
if you will). At nominal MPEG-1 video (352 x 240 x 30, 1.15 Mbit/sec)
rates, it is said that B-frames improves SNR by as much as 2 dB. (0.5
dB gain is usually considered worth-while in MPEG). However, at higher
bit rates, B- frames become less useful since they inherently do not
contribute to the progressive refinement of an image sequence (i.e.
not used as prediction by subsequent coded frames). Regardless,
B-frames are still politically controversial.
B pictures are interpolative in two ways: 1. predictions in the
bi-directional macroblocks are an average from block areas of two
pictures 2. B pictures "fill in" like a digital spackle the immediate
3-D video signal without contributing to the overall signal quality
beyond that immediate point in time. In other words, a B picture,
regardless of its internal make-up of macroblock types, has a life
limited only to itself. As mentioned before, B picture energy does not
propagate into other frames. In a sense, bits spent on B pictures are
wasted.
Why do some people hate B-frames?
A. Computational complexity, bandwidth, end-to-end delay, and picture
buffer size are the four B-frame Pet Peeves. Computational complexity
in the decoder is increased since some macroblock modes require
averaging between two block predictions (macroblock_motion_forward==1
&& macroblock_motion_backward==1).
Worst case, memory bandwidth is increased an extra 15.2 MByte/s
(assuming 4:2:0 chroma_format at Main Level), not including any half
pel or page-mode overhead) for this extra directional prediction. To
really rub it in, an extra picture buffer is needed to store the future
reference picture (backwards prediction frame). Finally, an extra
picture delay is introduced in the decoder since the frame used for
backwards prediction needs to be transmitted to the decoder and
reconstructed before the intermediate B-pictures in display order can
be decoded.
Cable television have been particularly adverse to B-frames since, for
CCIR 601 rate video, the extra picture buffer pushes the decoder DRAM
memory requirements past the magic 8- Mbit (1 Mbyte) threshold into the
evil realm of 16 Mbits (2 Mbyte).---- although 8-Mbits is fine for 352
x 480 B picture sequence. However, cable often forgets that DRAM does
not come in convenient high-volume (low cost) 8- Mbit packages as does
friendly 4-Mbit and 16-Mbit packages. In a few years, the cost
difference between 16 Mbit and 8 Mbit will become insignificant
compared to the bandwidth savings gain through higher compression. For
the time being, some cable boxes will start with 8-Mbit and allow
future drop-in upgrades to the full 16-Mbit.
How are interlaced and progressive pictures indicated in
MPEG?
The following tree may help illustrate the possible layers of
progressive and interlaced coding modes:
MPEG-2 sequence
/ \
progressive interlaced sequence
sequence / \
Field picture Frame picture
/ \
/ \
Frame or field prediction Frame MB prediction only
/ \
Field dct Frame dct
What does it mean to be compliant with MPEG ?
There are two areas of conformance/compliance in MPEG:
1. Compliant bitstreams
2. Compliant decoders
Technically speaking, video bitstreams consisting entirely of I-frames
are syntactically compliant with the MPEG specification. The I-frame
sequence simply utilizes a rather limited subset of the full syntax.
Compliant bitstreams must obey the range limits (e.g. motion vectors
ranges, bit rates, frame rates, buffer sizes) and permitted syntax
elements in the bitstream (e.g. chroma_format, B-pictures, etc).
Decoders, however, must be able to decode all combinations of legal
bitstreams.. For example, a decoder which is incapable of decoding P or
B frames is definitely not a Main Profile or Constrained Parameters
decoder! Likewise, full arithmetic precision must be obeyed before any
decoder can be called "MPEG compliant." The IDCT, inverse quantizer,
and motion compensated predictor must meet the accuracy requirements
defined in the MPEG document. Real-time conformance is more complicated
to measure than arithmetic precision, but it reasonable to expect that
decoders that skip frames on reasonable bitstreams are not likely to be
considered compliant.
What are Profiles and Levels?
A. MPEG-2 Video Main Profile and Main Level is analogous to MPEG-1's
CPB, with sampling limits at CCIR 601 parameters (720x480x30 Hz or
720x576x24 Hz). "Profiles" limit syntax (i.e. algorithms), whereas
"Levels" limit coding parameters (sample rates, frame dimensions, coded
bitrates, etc.). Together, Video Main Profile and Main Level
(abbreviated as MP@ML) normalize complexity within feasible limits of
1994 VLSI technology (0.5 micron), yet still meet the needs of the
majority of applications. MP@ML is the conformance point for most cable
and satellite TV systems.
[insert a description of each Profiles and Levels here]
Can MPEG-1 encode higher sample rates than 352 x 240 x 30 Hz ?
A. Yes. The MPEG-1 syntax permits sampling dimensions as high as 4095 x
4095 x 60 frames per second. The MPEG most people think of as "MPEG-1"
is really a kind of subset known as Constrained Parameters bitstream
(CPB).
What are Constrained Parameters Bitstreams?
MPEG-1 CPB are a limited set of sampling and bitrate parameters
designed to normalize decoder computational complexity, buffer size,
and memory bandwidth while still addressing the widest possible range
of applications. The parameter limits were intentionally designed to
permit decoder implementations integrated with 4 Megabits (512 Kbytes)
of DRAM.
Bitstream Parameter
Limit
pixels/line
704
lines/frame
480 or 576
pixels/frame
101,376 pixels
pixels/second
2,534,400
frames/sec
30 Hz
bit rate
1.86 Mbit/sec
buffer size
40 Kbytes
The sampling limits of CPB are bounded at the ever popular SIF rate:
396 macroblocks (101,376 pixels) per picture if the picture rate is
less than or equal to 25 Hz, and 330 macroblocks (84,480 pixels) per
picture if the picture rate is 30 Hz. The MPEG nomenclature loosely
defines a pixel or "pel" as a unit vector containing a complete
luminance sample and one fractional (0.25 in 4:2:0 format) sample from
each of the two chrominance (Cb and Cr) channels. Thus, the
corresponding bandwidth figure can be computed as:
352 samples/line x 240 lines/picture x 30 pictures/sec x 1.5
samples/pixel
or 3.8 Ms/s (million samples/sec) including chroma, but not including
blanking intervals. Since most decoders are capable of sustaining VLC
decoding at a faster rate than 1.8 Mbit/sec, the coded video bitrate
has become the most often waived parameter of CPB. An encoder which
intelligently employs the syntax tools should achieve SIF quality
saturation at about 2 Mbit/sec, whereas an encoder producing streams
containing only I (Intra) pictures might require as much as 8 Mbit/sec
to achieve the same video quality.
Why is Constrained Parameters so important?
A. It is an optimum point that allows (just barely) cost effective
VLSI implementations in 1992 technology (0.8 microns). It also
implies a nominal guarantee of interoperability for decoders and a
reasonable class of performance for encoders. Since CPB is the most
popular canonical MPEG-1 conformance point, MPEG devices which are not
capable of at least meeting SIF rates are usually not considered to be
true MPEG by industry.
Picture buffers (i.e. "frame stores") and coded data buffering
requirements for MPEG-1 CPB fit just snugly into 4 Mbit of memory
(DRAM).
Who uses constrained parameters bitstreams?
A. Principal CPB applications are Compact Disc video (White Book or
CD-I) and desktop video. Set-top TV decoders fall into a higher
sampling rate category known as "CCIR 601" or "Broadcast rate," which
as a rule of thumb, has sampling dimensions and bandwidth 4 times
that of SIF (Constrained Parameter sample rate limit).
Are there ways of circumventing constrained parameters bitstreams for
SIF class applications and decoders ?
A. Yes, some. Remember that CPB limits pictures by macroblock count
(or pixels/frame). 416 x 240 x 24 Hz sampling rates are still within
these constraints. Deviating from 352 samples/line could throw off many
decoder implementations which possess limited horizontal sample rate
conversion abilities. Some decoders do in fact include a few rate
conversion modes, with a filter usually implemented via binary taps
(shifts and adds). Likewise, the target sample rates are usually
limited or ratios (e.g. 640, 540, 480 pixels/line, etc.). Future MPEG
decoders will likely include on-chip arbitrary sample rate converters,
perhaps capable of operating in the vertical direction (although there
is little need of this in applications using standard TV monitors where
line count is constant, with the possible exception of windowing in
cable box graphical user interfaces).
Also, many CD videos are letterboxed at the 16:9 aspect ratio. The
actual coded and display sampling dimensions are 384 x 216 (note
384/216 = 16/9). These programs are typically movies coded at the more
manageable 24 frames/sec.
Are there any other conformance points like CPB for MPEG-1?
A. Undocumented ones, yes. A second generation of decoder chips
emerged on the market about 1 year after the first wave of SIF-class
decoders. Both LSI Logic and SGS-Thomson introduced CCIR 601 class
MPEG-1 video decoders to fill in the gap between canonical MPEG-1 (SIF)
and the emergence of Main Profile at Main Level (CCIR 601) MPEG-2
decoders. Under non-disclosure agreement, C-Cube had the CL- 950,
although since Q2'94, the CL-9100 is now the full MPEG-2 successor in
production. MPEG-1 decoders in the CCIR 601 class, or Main Level, were
all too often called MPEG-1.5 or MPEG-1++ decoders. For the first year
of operation, the Direct Broadcasting Satellite service in the United
States (Hughes Direct TV and Hubbards USSB) called only upon MPEG-1
syntax to represent interlaced video before switching to full MPEG-2
syntax.
What frame rates are permitted in MPEG?
A limited set is available for the choosing in MPEG-1 and the currently
defined set of Profiles and Levels of MPEG-2, although "tricks" could
be played with Systems-layer Time Stamps to convey non-standard picture
rates. The set is: 23.976 Hz (3-2 pulldown NTSC), 24 Hz (Film), 25 Hz
(PAL/SECAM or 625/60 video), 29.97 (NTSC), 30 Hz (drop-frame NTSC or
component 525/60), 50 Hz (double-rate PAL), 59.97 Hz (double rate
NTSC), and 60 Hz (double-rate, drop-frame NTSC/component 525/60
video).
Only 23.976, 24, 25, 29.97, and 30 Hz are within the conformance space
of Constrained Parameter Bitstreams and Main Level.
What areas can be improved upon to create a better syntax
than MPEG?
Several improvements can be made to the MPEG syntax while remaining
within the framework of block based coding. As implementation
technology improves with time, the ratio of computation to sample rate
can be increased for the same implementation cost. With each
evolutionary stage in the shrinking of the semiconductor lithography
process (line width), more complex coding methods become economically
realizable. Some of the well-known or well-anticipated areas for
improvement are described below:
Intra coding:
For intra pictures, subband methods such as wavelets combined with
improved quantization and entropy coders could gain as much as 2-4 dB
over MPEG Intra pictures. The problem becomes more complex when
considering the coding of Intra Macroblocks in mixed pictures, such as
P or B, since the extend of a subband must, in the simplest of
schemes, be limited to the dimensions of a macroblock.
Prediction error coding
One of the strongest gripes against MPEG is the use of the DCT for
decorrelation of prediction error blocks. One explanation is that the
DCT is suited for the statistical correlation of intra signals, but
less suited for the statistics of prediction error (Non-Intra) signals.
One common proposal is to replace the DCT with a Vector Quantizer.
Prediction error (Non-intra) blocks typically contain far fewer bits
than intra blocks. (The bits that comprise a Non-intra blocks can be
thought of as having been previously distributed over previous blocks
in previous pictures in the form of coefficients and side
information...)
Finer coding unit granularity�s:
The size of the transform block could be made smaller, larger, or both
(myriad of different sizes). Likewise, the size of the motion
compensation block can be made larger or smaller. The cost is more
complex semantics (more decoder complexity) and the overhead bits to
select the block size. Instead of sharing the same side information,
the blocks within the macroblock could be assigned their own motion
vectors, macroblock quantization scale factors, etc.
Many advanced techniques were in investigated by MPEG during the
formative stages of the specification, but were eventually eliminated
for falling below a threshold set for coding gain vs. implementation
complexity. Often, proposals presented a significant departure from the
main stream algorithms under consideration. Each bit added to the
syntax, or rule added to the semantics represents several gates to a
silicon implementation, or from a software perspective, an extra table,
if-then or case statement at multiple points in the decoding program.
What are the similarities and differences between MPEG and
H.263
During its formative stages, H.263 was known as "H.26P" or "H.26X". It
is an ITU-T standard for low-bitrate video and audio teleconferencing.
It is designed to be more efficient (at least 2dB) than H.261 for bit
rates below 64 kbits/sec (ISDN B channel). The primary target bit
rate, approximately 27,000 bits/sec, is the payload rate of the V.34
(a.k.a "V.Fast" or "V.Last") modem standard. In a typical scenario, 20
kbit/sec would be allocated for the video portion, and 6.5 kbit/sec for
the speech portion.
Since the H.261 syntax was defined in 1990, techniques and
implementation power have naturally improved. H.263 collects many of
the advanced methods proposed during MPEGs formative stages into a
syntax which shares a common basis more with MPEG-1 video than with
H.261.
The detailed differences and similarities are summarized below:
Sample rate, precision, and color space:
H.263 pictures are transmitted with QCIF dimensions. MPEG and JPEG
allow nearly any picture size to be described in the headers. A fixed
picture size promotes interoperability by forcing all implementors to
operate at a common rate, rather than by allowing implementors to get
away with whatever lowest sample rate the consumer can be tricked into
buying. Another reason for a fixed sample rate is that, unlike MPEG
which is generic, H.263 is geared towards a specific application
(teleconferencing). Other MPEG applications such as CD Video and Cable
TV define their own fixed parameters. Chromaticy is again YCbCr, 4:2:0
macroblock structure, and 8 bits of uniform sample precision.
[details deferred]
How would you describe MPEG to the Data Compression
expert?
A. MPEG video is a block-based coding scheme.
How does MPEG video really compare to TV, VHS, laserdisc ?
A. VHS picture quality can be achieved for film source video at about 1
million bits per second (with careful application of proprietary
encoding methods). Objective comparison of MPEG to VHS is complex.
The luminance response curve of VHS places -3 dB (50% response, the
common definition of bandlimit) at around analog 2 MHz (digital
equivalent to 200 samples/line). VHS chroma is considerably less dense
in the horizontal direction than MPEG's 4:2:0 signal (compare 80
samples/line equivalent to 176 !!). From a sampling density
perspective, VHS is superior only in the vertical direction (480
luminance lines compared to 240). When other analog factors are taken
into account, such as interfield crosstalk and the TV monitor Kell
factor, the perceptual vertical advantage becomes much less than 2:1.
VHS is also prone to such inconveniences as timing errors (an annoyance
addressed by time base correctors), whereas digital video is fully
discretized. Duplication processes for pre-recorded VHS tapes at high
speeds (5 to 15 times real time playback speed) introduces additional
handicaps. In gist, MPEG-1 at its nominal parameters can match VHSs
sexy low-pass-filtered look, but for critical sequences, is probably
overall inferior to a well mastered, well duplicated VHS tape.
With careful coding schemes, broadcast NTSC quality can be approximated
at about 3 Mbit/sec, and PAL quality at about 4 Mbit/sec for film
source video. Of course, sports sequences with complex spatial-
temporal activity should be treated with higher bit rates, in the
neighborhood of 5 and 6 Mbit/sec. Laserdisc is perhaps the most
difficult medium to make comparisons with.
First, the video signal encoded onto a laserdisc is composite, which
lends the signal to the familiar set of artifacts (reduced color
accuracy of YIQ, moirse patterns, crosstalk, etc). The medium's
bandlimited signal is often defined by laserdisc player manufacturers
and main stream publications as capable of rendering up to 425 TVL (or
frequencies with Nyquist at 567 samples/line). An equivalent component
digital representation would therefore have sampling dimensions of 567
x 480 x 30 Hz. The carrier-to-noise ratio of a laserdisc video signal
is typically better than 48 dB. Timing accuracy is excellent,
certainly better than VHS. Yet some of the clean characteristics of
laserdisc can be simulated with MPEG-1 signals as low as 1.15 Mbit/sec
(SIF rates), especially for those areas of medium detail (low spatial
activity) in the presence of uniform motion (affine motion vector
fields). The appearance of laserdisc or Super VHS quality can therefore
be obtained for many video sequences with low bit rates, but for the
more general class of images sequences, a bit rate ranging from 3 to 6
Mbit/sec is necessary.
What are the typical coded sizes for the MPEG frames?
Typical bit sizes for the three different picture types:
Level
I
P
B
Average
30 Hz SIF
@ 1.15 Mbit/sec
150,000
50,000
20,000
38,000
30 Hz CCIR 601
@ 4 Mbit/sec
400,000
200,000
80,000
130,000
Note: the above example is taken from a standard test sequence coded by
the Test Model method, with an I frame distance of 15 (N = 15), and a P
frame distance of 3 (M = 3).
Of course, among differing source material, scene changes, and use of
advanced encoder models these numbers can be significantly different.
At what bitrates is MPEG-2 video optimal?
The Test subgroup has defined a few example "Sweet spot" sampling
dimensions and bit rates for MPEG-2:
Dimensions
Coded rate
Application
352x480x24 Hz
(progressive)
2 Mbit/sec
Equivalent to VHS quality. Intended for film source video. Half
horizontal 601(HHR). Looks almost broadcast NTSC quality
544x480x30 Hz
(interlaced).
4 Mbit/sec
PAL broadcast quality (nearly full capture of 5.4 MHz luminance
signal). 544 samples matches the width of a 4:3 picture windowed
within 720 sample/line 16:9 aspect ratio via pan&scan
704x480x30
Hz.(interlaced)
6 Mbit/sec
Full CCIR 601 sampling dimensions
These numbers may be too ambitious. Bit rates of 3, 6, and 8 Mbit/sec
respectively provide transparent quality for the above application
examples when generated by a reasonably sophisticated encoder.
Why does film perform so well with MPEG ?
1. The frame rate is 24 Hz (instead of 30 Hz) which is a savings of
some 20%.
2. Film source video is inherently progressive. Hence no fussy
interlaced spectral frequencies.
3. The pre-digital source was severely oversampled (compare 352 x 240
SIF to 35 millimeter film at, say, 3000 x 2000 samples). This can
result in a very high quality signal, whereas most video cameras do not
oversample, especially in the vertical direction.
4. Finally, the spatial and temporal modulation transfer function (MTF)
characteristics (motion blur, etc) of film are more amenable to the
transform and quantization methods of MPEG.
What is the best compression ratio for MPEG ?
The MPEG sweet spot is about 1.2 bits/pel Intra and 0.35 bits/pixel
inter. Experimentation has shown that intra frame coding with the
familiar DCT-Quantization-Huffman hybrid algorithm achieves optimal
performance at about an average of 1.2 bits/sample or about 6:1
compression ratio. Below this point, artifacts become non-transparent.
Is there an MPEG file format?
The traditional descriptors that file formats provide in headers, such
image height, width, color space, etc., are already embedded within the
MPEG bitstream in the sequence header. Directory file formats are
described in the White Book and DVD specifications.
What is the Digital Video Disc (DVD) ?
In 1994, Toshiba united with Thomson Consumer Electronics, Pioneer, and
a handful of Hollywood studios to define a new 12 cm diameter compact
disc format for broadcast rate digital video. The new format basically
increases the effective areal storage density over the 1982 Red Book
format by some 6:1 (800 Mbytes vs 5 GBytes). This is achieved through
a combination of shorter laser wavelength, finer track pitch, inter-pit
pitch, and better optics. The thickness of the disc is reduced from the
Red Book's 1.2 millimeters to 0.6 millimeters. However, the new format
can be glue two 0.6 mm thick discs back-to-back, forming a double- size
disc 1.2 mm thick with a total capacity of 10 Gbytes. A two hour movie,
encoded onto only one side, would contain a video bistream average at 5
Mbit/sec. Or 10 Mbit/sec if distributed on both sides of a disc. Most
of the 6:1 gain is achieved though more efficient encoding of bits onto
the disc. Only a 2:1 factor comes purely from the reduction in
wavelength.
By comparison, today's double-sided analog video laserdiscs have a
diameter of 30 cm (571 cm^2 of usable area), and a thickness of 2.4
millimeters. Storage capacity is a maximum of 65 minutes per side.
A future potential format for HDTV may employ a blue wavelength laser
(0.4 microns), offering another 2:1 increase in areal density, or 20
Gbytes total. Other alternatives include larger disc sizes. For
example, if bit coding at DVD areal densities were applied to the
familiar 30 cm disc, the average bitrate for the 65 minutes of video
per side would be nearly 70 Mbit/sec !!
What is the MPEG committee ?
In fact, MPEG is a nickname. The official title is: ISO/IEC JTC1 SC29 WG11.
ISO: International Organization for Standardization
IEC: International Electrotechnical Commission
JTC1: Joint Technical Committee 1
SC29: Sub-committee 29
WG11: Working Group 11 (moving pictures with... uh, audio)
What ever happened to MPEG-3 ?
MPEG-3 was to have targeted HDTV applications with sampling dimensions
up to 1920 x 1080 x 30 Hz and coded bitrates between 20 and 40
Mbit/sec. It was later discovered that with some (syntax compatible)
fine tuning, MPEG-2 and MPEG-1 syntax worked very well for HDTV rate
video. The key is to maintain an optimal balance between sample rate
and coded bit rate.
Also, the standardization window for HDTV was rapidly closing. Europe
and the United States were on the brink of committing to
analog-digital subnyquist hybrid algorithms (D-MAC, MUSE, et al). By
1992, European all-digital projects such as HD-DIVINE and VADIS
demonstrated better picture quality with respect to bandwidth using the
MPEG syntax. In the United States, the Sarnoff/NBC/Philips/Thomson
HDTV consortium had used MPEG-1 syntax from the beginning of its
all-digital proposal, and with the exception of motion artifacts (due
to limited search range in the encoder), was deemed to have the best
picture quality of all three digital proponents in the early 1993
bake-off. HDTV is now part of the MPEG-2 High-1440 Level and High Level
toolkit.
Why bother having an MPEG-2 ?
A. MPEG-1 was optimized for CD-ROM or applications at about 1.5
Mbit/sec. Video was strictly non- interlaced (i.e. progressive). The
international cooperation executed well enough for MPEG-1, that the
committee began to address applications at broadcast TV sample rates
using the CCIR 601 recommendation (720 samples/line by 480 lines per
frame by 30 frames per second or about 15.2 million samples/sec
including chroma) as the reference.
Unfortunately, today's TV scanning pattern is interlaced. This
introduces a duality in block coding: do local redundancy areas
(blocks) exist exclusively in a field or a frame.(or a particle or
wave) ? The answer of course is that some blocks are one or the other
at different times, depending on motion activity. The additional man
years of experimentation and implementation between MPEG-1 and MPEG-2
improved the method of block-based transform coding.
It is often remarked that MPEG-2 spent several hundred man years and
10s of millions of dollars yet only gained 20% coding efficiency over
MPEG-1 for interlaced video signals. However, the collaborative
process brought companies together, and from that came a standard well
agreed upon. In many ways, the political achievement dwarfs the
technical one. Also, MPEG-2 was exploratory. Coding of interlaced
video was unknown territory. It took some considerable convincing to
demonstrate that a simple syntax, akin to MPEG-1, was as efficient as
other proposals. Left by themselves, each company would probably have
produced a diverse scope of syntax.
Is MPEG patented ?
Many of the companies which participated in the MPEG committee have
indicated that they hold patents to fundamental elements of the MPEG
syntax and semantics. Already, the group known as the "IRT consortium"
(CCETT, IRT, et al) have defined royalty fees and licensing agreements
for OEMs of MPEG Layer I and II audio encoders and decoders. The fee
is $1 USD per audio channel in small quantities, and $0.50 USD per
channel in large quantities.
A royalty and licensing agreement has yet to be reached among holders
of Video and Systems patents, however the figure has already been
agreed upon, ranging from $3 to $4 per implementation. Whether it is
retroactively applicable or not to products already sold, or whether it
is possible to avoid the patents via approximation techniques, is not
known. The non-profit organization,CableLabs (Boulder, Colorado), is
responsible for leading the MPEG Intellectual Property Rights effort
(known canonically as the "MPEG Patent Pool."). An agreement is
expected by mid 1995.
In order to reach the IS (International Standard) document stage, all
parties must have sent in a letter to ISO stating they agree to license
their intellectual property on fair and reasonable terms,
indiscriminately. For MPEG-1 and MPEG-2, this was accomplished in mid
1993.
Companies which hold patents often cross-license each other. Each
party does not have to pay royalties to one another.
What is White Book
The White Book specifies the file structure and indexing of multiplexed
MPEG video and audio streams. White Book also specifies the Karaoke
application's reference table which describes programs and their sector
locations. At the lowest layer, White Book builds upon the CD-ROM XA
spec.. Extension data includes screen pointing devices, address list of
all Intra pictures within a program, CD version number, Closed Caption
data, and information indexing of MPEG still pictures.
The specific MPEG parameter definitions of White Book are:
Audio coding method: MPEG-1 Layer II
Sampling rate: 44.1 kHz
Coded bit rate: 224 Kbits/sec
Mode: stereo, dual channel, or intensity stereo
Video coding method: MPEG-1
Permitted sample rates:
352 pixels/line x 240 lines/frame x 29.97 frames/sec (NTSC rate)
352 pixels/line x 240 lines/frame x 23.976 frames/sec (NTSC film rate)
352 pixels/line x 288 lines/frame x 25 frame/sec (PAL rate)
Maximum bitrate: 1.1519291 bits/sec
Recommendations include:
pixel aspect ratios: 1.0950 (352x240) or 0.9157 (352 x 288)
Intra pictures be placed at least once every 2 seconds.
Still pictures: ("Intra" picture_coding_type only)
Normal res: 352 x 240 or 352 x 288 (maximum 46 Kbytes coded size)
Double res: 704 x 480 or 704 x 576 (maximum 224 Kbytes coded size)
The other books are:
Red Book: this is the original Compact Disc Audio specification (circa
1980). All other books (Yellow, Green, Orange, White) are identical at
the low-level, sharing a common base with Red Book. This grandfather
specification defines sectors, tracks, and channel coding (8/14 EFM
outer forward error correction (FEC), 8-bit polynomial interleaved
Reed-Soloman inner forward error correction, etc), and physical
parameters (disc diameter 12 cm, laser wavelength 0.8 microns, track
pitch, land-to-pit spacing, digital modulation, etc.).
Yellow Book: first CD-ROM specification (circa 1986). Later appended
by the CD-ROM XA spec.
Green Book: CD-I (Compact Disc Interactive).
Orange Book: Kodak Photo CD
ISO 9660: (circa 1988) describes file structure for CD-ROM XA (circa
1988). Similar to MS-DOS, filenames are case insensitive and limited to
8 characters, and 3 extension characters (8.3 format). Many CD-ROMs
containing MPEG are nothing more than Yellow Book CD which treat
multiplexed video and audio bitstreams as an ordinary file.
Further information can be retrieved from:
Philips Consumer Electronics B.V.
Coordination Office Optical & Magnetic Media Systems
Building SWA-1
P.O. Box 80002
5600 JB Eindhoven
The Netherlands
Tel: +31 40 736409
Fax: +31 40 732113
What are some typical picture sizes and their associated
applications ?
352 x 240 SIF. CD WhiteBook Movies, video games.
352 x 480 HHR. VHS equivalent
480 x 480 Bandlimited (4.2 Mhz) broadcast NTSC.
544 x 480 Laserdisc, D-2, Bandlimited PAL/SECAM.
640 x 480 Square pixel NTSC
720 x 480 CCIR 601. Studio D-1. Upper limit of Main Level.
Future topics:
How are MPEG video and audio streams synchronized?
What is Digital Video Cassette (DVC) ?
How does the D-VHS format encode MPEG signals?
What is MPEG-4 ?
The high level and low level differences between MPEG, JPEG, H.261, and H.263
MPEG in applications
More on DVD.
Details on DVB
Implementations (semiconductor chips)
Software Complexity and performance. Well known speedup methods.
MPEG software on the Internet (audio, video, systems)
Specific MPEG articles in literature.
Current activities of MPEG-4
MPEG Compliance bitstreams
-----
cfogg@chromatic.com
How does MPEG syntax facilitate parallelism ?
For MPEG-1, slices may consist of an arbitrary number of macroblocks.
They can be independently decoded once the picture header side
information is known. For parallelism below the slice level, the coded
bitstream must first be mapped into fixed-length elements. Further,
since macroblocks have coding dependencies on previous macroblocks
within the same slice, the data hierarchy must be pre-processed down to
the layer of DC DCT coefficients. After this, blocks may be
independently inverse transformed and quantized, temporally predicted,
and reconstructed to buffer memory. Parallelism is usually more of a
concern for encoders. In many encoders today, block matching (motion
estimation) and some rate control stages (such as activity and/or
complexity measures) are processed for macroblocks independently.
Finally, with the exception that all macroblock rows in Main Profile
MPEG-2 bitstreams must contain at least one slice, an encoder has the
freedom to choose the slice structure.
What is the MPEG color space and sample precision?
MPEG strictly specifies the YCbCr color space, not YUV or YIQ or YPbPr
or YDrDb or any other many fine varieties of color difference spaces.
Regardless of any bitstream parameters, MPEG-1 and MPEG-2 Video Main
Profile specify the 4:2:0 chroma_format, where the color difference
channels (Cb, Cr) have half the "resolution" or sample grid density in
both the horizontal and vertical direction with respect to luminance.
MPEG-2 High Profile includes an option for 4:2:2 chroma_format, as does
the MPEG 4:2:2 Profile (a.k.a. Studio Profile) naturally. Applications
for the 4:2:2 format can be found in professional broadcasting,
editing, and contribution-quality distribution environments. The
drawback of the 4:2:2 format is simply that it increases the size of
the macroblock from six 8x8 blocks (4:2:0) to eight, while increasing
the frame buffer size and decoding bandwidth by the same amount (33
%). This increase places the buffering memories well past the magic
16-Mbit limit for semiconductor DRAM devices, assuming the pictures are
stored with a maximum of 414,720 pixels (720 pixels/line x 576
lines/frame). The maximum allowable pixel resolution could be reduced
by 1/3 to compensate (e.g. 544 x 576). However, if a hardware decoders
operate on a macroblock basis in the pipeline, on-chip static memories
(SRAM) will increase by 1/3. The benefits offered by 1/3 more pixels
generally outweighs full vertical chrominance resolution. Other
arguments favoring 4:2:0 over 4:2:2 include:
Vertical decimation increases compression efficiency by reducing
syntax overhead posed in an 8 block (4:2:2) macroblock structure.
You're compressing the hell out of the video signal, so what possible
difference can the 0:0:2 chromiance high-pass make?
Is 4:2:0 the same as 4:1:1 ?
No, no, definitely no. The following table illustrates the nuances
between the different chroma formats for a frame with pixel dimensions
of 720 pixels/line x 480 lines/frame.
CCIR 601 (60 Hz) image Chroma sub-sampling factors
format Y Cb, Cr Vertical Horizontal
chroma
format
pixels/
line
Y
lines/
frame
Y
pixels/
line
Cb, Cr
lines/
frame
Cb, Cr
horizontal
subsampling
factor
vertical
subsampling
factor
4:4:4
720
480
720
480
none
none
4:2:2
720
480
360
480
2:1
none
4:2:0
720
480
360
240
2:1
2:1
4:1:1
720
480
180
480
4:1
none
4:1:0
720
480
180
120
4:1
4:1
3:2:2, 3:1:1, and 3:1:0 are less common variations, but have been
documented. As shocking as it may seem, the 4:1:0 ratio was used by
Intels DVI for several years.
The 130 microsecond gap between successive 4:2:0 lines in progressive
frames, and 260 microsecond gap in interlaced frames, can introduce
some difficult vertical frequencies, but most can be alleviated through
pre- processing.
What is the sample precision of MPEG ? How many colors
can MPEG represent ?
By definition, MPEG samples have no more and no less than 8-bits
uniform sample precision (256 quantization levels). For luminance
(which is unsigned) data, black corresponds to level 0, white is level
255. However, in CCIR recommendation 601 chromaticy, luminance (Y)
levels 0 through 14 and 236 through 255 are reserved for blanking
signal excursions. MPEG currently has no such clipped excursion
restrictions, although decoder might take care to insure active samples
do not exceed these limits. With three color components per pixel, the
total combination is roughly 16.8 million colors (i.e. 24-bits).
How are the subsampled chroma samples cited ?
It is moderately important to properly co-site chroma samples,
otherwise a sort of chroma shifting effect (exhibited as a halo) may
result when the reconstructed video is displayed. In MPEG-1 video, the
chroma samples are exactly centered between the 4 luminance samples
(Fig 1.) To maintain compatibility with the CCIR 601 horizontal
chroma locations and simplify implementation (eliminate need for phase
shift), MPEG-2 chroma samples are arranged as per Fig.2.
Y Y Y Y Y Y Y Y YC Y YC Y
C C C C
Y Y X Y Y Y Y Y YC Y YC Y
Y Y Y Y Y Y Y Y YC Y YC Y
C C C C
Y Y Y Y Y Y Y Y YC Y YC Y
Fig.1 MPEG-1 Fig.2 MPEG-2 Fig.3 MPEG-2 and
4:2:0 organization 4:2:0 organization CCIR Rec. 601
4:2:2 organization
How do you tell an MPEG-1 bitstream from an MPEG-2
bitstream ?
A. All MPEG-2 bitstreams must contain specific extension headers that
immediately follow MPEG-1 headers. At the highest layer, for example,
the MPEG-1 style sequence_header() is followed by sequence_extension().
Some extension headers are specific to MPEG-2 profiles. For example,
sequence_scalable_extension() is not allowed in Main Profile
bitstreams.
A simple program need only scan the coded bitstream for byte-aligned
start codes to determine whether the stream is MPEG-1 or MPEG-2.
What are start codes?
These 32-bit byte-aligned codes provide a mechanism for cheaply
searching coded bitstreams for commencement of various layers of video
without having to actually parse variable-length codes or perform any
decoder arithmetic. Start codes also provide a mechanism for
resynchronization in the presence of bit errors. A start code may be
preceded by an arbitrary number of zero bytes. The zero bytes can be
use to guarantee that a start code occurs within a certain location, or
by rate control to increase the bitrate of a coded bitstream.
Coded block pattern
Coded block pattern:
(CBP --not to be confused with Constrained Parameters!) When the frame
prediction is particularly good, the displaced frame difference(DFD, or
temporal macroblock prediction error) tends to be small, often with
entire block energy being reduced to zero after quantization. This
usually happens only at low bit rates. Coded block patterns prevent
the need for transmitting EOB symbols in those zero coded blocks.
Coded block patterns are transmitted in the macroblock header only if
the macrobock_type flag indicates so.
Why is the DC value always divided by 8 ?
Clarification point: The DC value of Intra coded blocks is quantized by
a constant stepsize of 8 only in MPEG-1, rendering the 11-bit dynamic
range of the IDCT DC coefficient to 8-bits of accuracy. MPEG-2 allows
for DC precision of 8, 9, 10, or 11 bits. The quantization stepsize is
fixed for the duration of the picture, set by the intra_dc_precision
flag in the picture_extension_header().
Why is there a special VLC for DCT_coefficient_first:?
Since the coded_block_pattern in NON-INTRA macroblocks signals every
possible combination of all-zero valued and non-zero blocks, the
dct_coef_first mechanism assigns a different meaning to the VLC
codeword (run = 0, level =+/- 1) that would otherwise represent EOB
(10) as the first coefficient in the zig-zag ordered Run-Level token
list.
What�s the deal with End of Block ?
Saves unnecessary run-length codes. At optimal bitrates, there tends
to be few AC coefficients concentrated in the early stages of the
zig-zag vector. In MPEG-1, the 2-bit length of EOB implies that there
is an average of only 3 or 4 non-zero AC coefficients per block. In
MPEG-2 Intra (I) pictures, with a 4-bit EOB code in Table 1, this
estimate is between 9 and 16 coefficients. Since EOB is required for
all coded blocks, its absence can signal that a syntax error has
occurred in the bitstream.
What�s this �Macroblock stuffing,� dammit ?:
A genuine pain for VLSI implementations, macroblock stuffing was
included in MPEG-1 to maintain smoother, constant bitrate control for
encoders. However, with normalized complexity/activity measures and
buffer management performed a priori (before coding of the macroblock,
for example) and local monitoring of coded data buffer levels now a
common operation in encoders, (e.g. MPEG-2 encoder Test Model), the
need for such localized bitrate smoothing evaporated. Stuffing can be
achieved through slice start code padding if required. A good rule of
thumb is: if you find often yourself wishing for stuffing more than
once per slice, you probably don't have a very good rate control
algorithm. Nonetheless, to avoid any temptation, macroblock stuffing
is now illegal in MPEG-2 (A general syntax restriction brought to you
by the Implementation Studies Subgroup!)
What�s the deal with slice_vertical_position and
macroblock_address_increment?
The absolute position of the first macroblock within a slice is known
by the combination of slice_vertical_position and the
macroblock_address_increment. Therefore, the proper place of a lost
slice found in a highly corrupt bitstream can be located exactly within
the picture. These two syntax elements are also the only known means
of detecting slice gaps----areas of the picture which are not
represented with any information (including skipped macroblocks). A
slice gap occurs when the current macroblock address of the first
macroblock in a slice is greater than the previous macroblock address
by more than 1 macroblock unit. A slice overlap occurs when the current
macroblock address is less than or equal to the previous macroblocks
address. The previous macroblock in both instances is the last known
macroblock within the previous slice. Because of the semantic
interpretation of slice gaps and overlaps, and because of the syntactic
restrictions for slice_vertical_position and
macroblock_address_increment, it is not syntactically possible for a
skipped macroblock to be represented in the first and last positions of
a slice. In the past, some (bad) encoders would attempt to signal a
run of skipped macroblocks to the end of the slice. These evil skipped
macroblocks should be interpreted by a compliant decoder as a gap, not
as a string of skipped macroblocks.
What is meant by modified Huffman VLC tables:
The VLC tables in MPEG are not Huffman tables in the true sense of
Huffman coding, but are more like the tables used in Group 3 fax. They
are entropy constrained, that is, non-downloadable and optimized for a
limited range of bit rates (sweet spots). A better way would be to say
that the tables are optimized for a range of ratios of bit rate to
sample rate (e.g. 0.25 bits/pixel to 1.0 bits/pixel). With the
exception of a few codewords, the larger tables were carried over from
the H.261 standard drafted in the year 1990. This includes the AC
run-level symbols, coded_block_pattern, and macroblock_address_increment.
MPEG-2 added an "Intra table," also called "Table 1". Note that the
dct_coefficient tables assume positive/negative coefficient PMF
symmetry.
How does MPEG handle 3:2 pulldown?
MPEG-1 video decoders had to decide for themselves when to perform 3:2
pulldown if it was not indicated in the presentation time stamps (PTS)
of the Systems layer bitstream. MPEG-2 provides two flags
(repeat_first_field, and top_field_first) which explicitly describe
whether a frame or field is to be repeated. In progressive sequences,
frames can be repeated 2 or 3 times. Simple and Main Profile limit are
limited to repeated fields only. It is a general syntactic restriction
that repeat_first_field can only be signaled (value ==1) in a frame
structured picture. It makes little sense to repeat field pictures in
an interlaced video signal since the whole process of 3:2 pulldown
conversion was meant to convert progressive, film sequences to the
display frame rate of interlaced television.
In the most common scenario, a film sequence will contain 24 frames
every second. The bit_rate element in the sequence header will
indicate 30 frames/sec, however. On average, every other coded frame
will signal a repeat field (repeat_first_field==1) to pad the frame
rate from 24 Hz to 30 Hz:
(24 coded frames/sec)*(2 fields/coded frame)*(5 display fields/4 coded
fields) = 30 display frames/sec
After all this standardization, what�s left for research?
A . Despite the fact that a comprehensive worldwide standard now exists
for digital video, many areas remain wide open for research: advanced
encoding and pre-processing, motion estimation, macroblock decision
models, rate control and buffer management in editing environments,
implementation complexity reduction, etc. Many areas have yet to be
solved ... (and discovered)..
Are some encoders better than others ?
A. Definitely. For example, the motion estimation search range of a
has great influence over final picture quality. At a certain point a
very large range can actually become detrimental (it may encourage
large differential motion vectors). Practical ranges are usually
between +/- 15 and +/- 32. As the range doubles, for instance, the
search area quadruples. (like the classic relationship between in
increase in linear vs. area).
Rate control marks a second tell-tale area where some encoders perform
significantly better than others.
And finally, the degree of "pre-processing" (now a popular buzzword in
the business) signals that the encoder belongs to an elite marketing
class.
Is the encoder standardized ?
A. The encoder rests just outside the normative scope of the standard,
as long as the bitstreams it produces are compliant. The decoder,
however, is almost deterministic: a given bitstream should reconstruct
to a unique set of pictures. However, since the IDCT function is the
ONLY non-normative stage in the decoder, an occasional error of a Least
Significant Bit per prediction iteration is permitted. The designer is
free to choose among many DCT algorithms and implementations. The IEEE
1180 test referenced in Annex A of the MPEG-1 (ISO/IEC 11172-2) and
MPEG-2 (ISO/IEC 13818-2) Video specifications spells out the
statistical mismatch tolerance between the Reference IDCT, which is a
separable 8x1 "Direct Matrix" DCT implemented with 64-bit floating
point accuracy, and the IDCT you are testing for compliance.
What is the TM (Test Model) ?
What is the TM rate control and adaptive quantization technique ?
A. The Test model (MPEG-2) and Simulation Model (MPEG-1) were not, by
any stretch of the imagination, meant to epitomize state-of-the art
encoding quality. They were, however, designed to exercise the syntax,
verify proposals, and test the relative compression performance of
proposals in a timely manner that could be duplicated by
co-experimenters. Without simplicity, there would have been no doubt
endless debates over model interpretation. Regardless of all else,
more advanced techniques would probably trespass into proprietary
territory.
The final test model for MPEG-2 is TM version 5b, a.k.a. TM version 6,
produced in March 1993 (the time when the MPEG-2 video syntax was
frozen). The final MPEG-1 simulation model is version 3 (SM-3). The
MPEG-2 TM rate control method offers a dramatic improvement over the SM
method. TM adds more accurate estimation of macroblock complexity
through use of limited a priori information. Macroblock quantization
adjustments are computed on a macroblock basis, instead of
once-per-macroblock row (which in the SM-3 case consisted of an entire
slice).
How does the TM work?
Rate control and adaptive quantization are divided into three steps:
Step One: Target Bit Allocation
In Complexity Estimation, the global complexity measures assign
relative weights to each picture type (I,P,B). These weights (Xi, Xp,
Xb) are reflected by the typical coded frame size of I, P, and B
pictures (see typical frame size discussion). I pictures are usually
assigned the largest weight since they have the greatest stability
factor in an image sequence and contain the most new information in a
sequence. B pictures are assigned the smallest weight since B energy
do not propagate into other pictures and are usually more highly
correlated with neighboring P and I pictures than P pictures are.
The bit target for a frame is based on the frame type, the remaining
number of bits left in the Group of Pictures (GOP) allocation, and the
immediate statistical history of previously coded pictures (sort of a
moving average global rate control, if you will).
Step Two: Rate Control via Buffer Monitoring
Rate control attempts to adjust bit allocation if there is significant
difference between the target bits (anticipated bits) and actual coded
bits for a block of data. If the virtual buffer begins to overflow,
the macroblock quantization step size is increased, resulting in a
smaller yield of coded bits in subsequent macroblocks. Likewise, if
underflow begins, the step size is decreased. The Test Model
approximates that the target picture has spatially uniform distribution
of bits. This is a safe approximation since spatial activity and
perceived quantization noise are almost inversely proportional. Of
course, the user is free to design a custom distribution, perhaps
targeting more bits in areas that contain more complex yet highly
perceptible data such as text.
Step Three: Adaptive Quantization
The final step modulates the macroblock quantization step size obtained
in Step 2 by a local activity measure. The activity measure itself is
normalized against the most recently coded picture of the same type (I,
P, or B). The activity for a macroblock is chosen as the minimum among
the four 8x8 block luminance variances. Choosing the minimum block is
part of the concept that a macroblock is no better than the block of
highest visible distortion (weakest link in the chain).
Decision:
[deferred to later date]
Can motion vectors be used to determine object velocity?
Motion vector information cannot be reliably used as a means of
determining object velocity unless the encoder model specifically set
out to do so. First, encoder models that optimize picture quality
generate vectors that typically minimize prediction error and,
consequently, the vectors often do not represent true object
translation from picture-to-picture. Standards converters that
resample one frame rate to another (as in NTSC to PAL) use different
methods (motion vector field estimation, edge detection, et al) that
are not concerned with Rate-Distortion theory. Second, motion vectors
are not transmitted for all macroblocks anyway.
Is it possible to code interlaced video with MPEG-1 syntax?
A. Two methods can be applied to interlaced video that maintain
syntactic compatibility with MPEG-1 (which was originally designed for
progressive frames only). In the field concatenation method, the
encoder model can carefully construct predictions and prediction errors
that realize good compression but maintain field integrity (distinction
between adjacent fields of opposite parity). Some pre-processing
techniques can also be applied to the interlaced source video that
would, e.g., lessen sharp vertical frequencies.
This technique is not terribly efficient of course. On the other hand,
if the original source was progressive (e.g. film), then it is more
trivial to convert the interlaced source to a progressive format before
encoding. (MPEG-2 would then only offer slightly superior performance
through such MPEG-2 enhancements as greater DC coefficient precision,
non-linear mquant, intra VLC, etc.) Reconstructed frames are usually
re- interlaced in the Display process following the decoding stages.
The second syntactically compatible method codes fields as separate
pictures. Rumors have spread that this approach does not quiet work
nearly as well as the pretend its really a frame method.
Can MPEG be used to code still frames ?
Yes. MPEG Intra pictures are similar to baseline sequential JPEG pictures.
There are, of course, advantages and disadvantages to using MPEG over
JPEG to represent still pictures.
Disadvantages:
1. MPEG has only one color space (YCbCr)
2. MPEG-1 and MPEG-2 Main Profile luma and chroma share quanitzation
and VLC tables (4:2:0 chroma_format)
3. MPEG-1 is syntactically limited to 4k x 4k images, and 16k x 16k for MPEG-2.
Advantages:
1. MPEG possesses adaptive quantization which permits better rate
control and spatial masking.
2. With its limited still image syntax, MPEG averts any temptation to
use unnecessary, expensive, and academic encoding methods that have
little impact on the overall picture quality (you know who you are).
3. Philips' CD-I spec. has a requirement for a MPEG still frame mode,
with double SIF image resolution. This is technically feasible mostly
thanks to the fact that only one picture buffer is needed to decode a
still image instead of the 2.5 to 3 buffers needed for IPB sequences.
Why was the 8x8 DCT size chosen?
A. Experiments showed little compaction gains could be achieved with
larger transform sizes, especially in light of the increased
implementation complexity. A fast DCT algorithm will require roughly
double the number of arithmetic operations per sample when the linear
transform point size is doubled. Naturally, the best compaction
efficiency has been demonstrated using locally adaptive block sizes
(e.g. 16x16, 16x8, 8x8, 8x4, and 4x4) [See Gary Sullivan and Rich
Baker "Efficient Quadtree Coding of Images and Video," ICASSP 91, pp
2661-2664.].
Inevitably, adaptive block transformation sizes introduce additional
side information overhead while forcing the decoder to implement
programmable or hardwired recursive DCT algorithms. If the DCT size
becomes too large, then more edges (local discontinuities) and the like
become absorbed into the transform block, resulting in wider
propagation of Gibbs (ringing) and other unpleasant phenomena.
Finally, with larger transform sizes, the DC term is even more
critically sensitive to quantization noise.
Why was the 16x16 prediction size chosen?
The 16x16 area corresponds to the Least Common Multiple (LCM) of 8x8
blocks, given the normative 4:2:0 chroma ratio. Starting with medium
size images, the 16x16 area provides a good balance between side
information overhead & complexity and motion compensated prediction
accuracy. In gist, experiments showed that the 16x16 was a good
trade-off between complexity and coding efficiency.
What do B-pictures buy you?
A. Since bi-directional macroblock predictions are an average of two
macroblock areas, noise is reduced at low bit rates (like a 3-D filter,
if you will). At nominal MPEG-1 video (352 x 240 x 30, 1.15 Mbit/sec)
rates, it is said that B-frames improves SNR by as much as 2 dB. (0.5
dB gain is usually considered worth-while in MPEG). However, at higher
bit rates, B- frames become less useful since they inherently do not
contribute to the progressive refinement of an image sequence (i.e.
not used as prediction by subsequent coded frames). Regardless,
B-frames are still politically controversial.
B pictures are interpolative in two ways: 1. predictions in the
bi-directional macroblocks are an average from block areas of two
pictures 2. B pictures "fill in" like a digital spackle the immediate
3-D video signal without contributing to the overall signal quality
beyond that immediate point in time. In other words, a B picture,
regardless of its internal make-up of macroblock types, has a life
limited only to itself. As mentioned before, B picture energy does not
propagate into other frames. In a sense, bits spent on B pictures are
wasted.
Why do some people hate B-frames?
A. Computational complexity, bandwidth, end-to-end delay, and picture
buffer size are the four B-frame Pet Peeves. Computational complexity
in the decoder is increased since some macroblock modes require
averaging between two block predictions (macroblock_motion_forward==1
&& macroblock_motion_backward==1).
Worst case, memory bandwidth is increased an extra 15.2 MByte/s
(assuming 4:2:0 chroma_format at Main Level), not including any half
pel or page-mode overhead) for this extra directional prediction. To
really rub it in, an extra picture buffer is needed to store the future
reference picture (backwards prediction frame). Finally, an extra
picture delay is introduced in the decoder since the frame used for
backwards prediction needs to be transmitted to the decoder and
reconstructed before the intermediate B-pictures in display order can
be decoded.
Cable television have been particularly adverse to B-frames since, for
CCIR 601 rate video, the extra picture buffer pushes the decoder DRAM
memory requirements past the magic 8- Mbit (1 Mbyte) threshold into the
evil realm of 16 Mbits (2 Mbyte).---- although 8-Mbits is fine for 352
x 480 B picture sequence. However, cable often forgets that DRAM does
not come in convenient high-volume (low cost) 8- Mbit packages as does
friendly 4-Mbit and 16-Mbit packages. In a few years, the cost
difference between 16 Mbit and 8 Mbit will become insignificant
compared to the bandwidth savings gain through higher compression. For
the time being, some cable boxes will start with 8-Mbit and allow
future drop-in upgrades to the full 16-Mbit.
How are interlaced and progressive pictures indicated in
MPEG?
The following tree may help illustrate the possible layers of
progressive and interlaced coding modes:
MPEG-2 sequence
/ \
progressive interlaced sequence
sequence / \
Field picture Frame picture
/ \
/ \
Frame or field prediction Frame MB prediction only
/ \
Field dct Frame dct
What does it mean to be compliant with MPEG ?
There are two areas of conformance/compliance in MPEG:
1. Compliant bitstreams
2. Compliant decoders
Technically speaking, video bitstreams consisting entirely of I-frames
are syntactically compliant with the MPEG specification. The I-frame
sequence simply utilizes a rather limited subset of the full syntax.
Compliant bitstreams must obey the range limits (e.g. motion vectors
ranges, bit rates, frame rates, buffer sizes) and permitted syntax
elements in the bitstream (e.g. chroma_format, B-pictures, etc).
Decoders, however, must be able to decode all combinations of legal
bitstreams.. For example, a decoder which is incapable of decoding P or
B frames is definitely not a Main Profile or Constrained Parameters
decoder! Likewise, full arithmetic precision must be obeyed before any
decoder can be called "MPEG compliant." The IDCT, inverse quantizer,
and motion compensated predictor must meet the accuracy requirements
defined in the MPEG document. Real-time conformance is more complicated
to measure than arithmetic precision, but it reasonable to expect that
decoders that skip frames on reasonable bitstreams are not likely to be
considered compliant.
What are Profiles and Levels?
A. MPEG-2 Video Main Profile and Main Level is analogous to MPEG-1's
CPB, with sampling limits at CCIR 601 parameters (720x480x30 Hz or
720x576x24 Hz). "Profiles" limit syntax (i.e. algorithms), whereas
"Levels" limit coding parameters (sample rates, frame dimensions, coded
bitrates, etc.). Together, Video Main Profile and Main Level
(abbreviated as MP@ML) normalize complexity within feasible limits of
1994 VLSI technology (0.5 micron), yet still meet the needs of the
majority of applications. MP@ML is the conformance point for most cable
and satellite TV systems.
[insert a description of each Profiles and Levels here]
Can MPEG-1 encode higher sample rates than 352 x 240 x 30 Hz ?
A. Yes. The MPEG-1 syntax permits sampling dimensions as high as 4095 x
4095 x 60 frames per second. The MPEG most people think of as "MPEG-1"
is really a kind of subset known as Constrained Parameters bitstream
(CPB).
What are Constrained Parameters Bitstreams?
MPEG-1 CPB are a limited set of sampling and bitrate parameters
designed to normalize decoder computational complexity, buffer size,
and memory bandwidth while still addressing the widest possible range
of applications. The parameter limits were intentionally designed to
permit decoder implementations integrated with 4 Megabits (512 Kbytes)
of DRAM.
Bitstream Parameter
Limit
pixels/line
704
lines/frame
480 or 576
pixels/frame
101,376 pixels
pixels/second
2,534,400
frames/sec
30 Hz
bit rate
1.86 Mbit/sec
buffer size
40 Kbytes
The sampling limits of CPB are bounded at the ever popular SIF rate:
396 macroblocks (101,376 pixels) per picture if the picture rate is
less than or equal to 25 Hz, and 330 macroblocks (84,480 pixels) per
picture if the picture rate is 30 Hz. The MPEG nomenclature loosely
defines a pixel or "pel" as a unit vector containing a complete
luminance sample and one fractional (0.25 in 4:2:0 format) sample from
each of the two chrominance (Cb and Cr) channels. Thus, the
corresponding bandwidth figure can be computed as:
352 samples/line x 240 lines/picture x 30 pictures/sec x 1.5
samples/pixel
or 3.8 Ms/s (million samples/sec) including chroma, but not including
blanking intervals. Since most decoders are capable of sustaining VLC
decoding at a faster rate than 1.8 Mbit/sec, the coded video bitrate
has become the most often waived parameter of CPB. An encoder which
intelligently employs the syntax tools should achieve SIF quality
saturation at about 2 Mbit/sec, whereas an encoder producing streams
containing only I (Intra) pictures might require as much as 8 Mbit/sec
to achieve the same video quality.
Why is Constrained Parameters so important?
A. It is an optimum point that allows (just barely) cost effective
VLSI implementations in 1992 technology (0.8 microns). It also
implies a nominal guarantee of interoperability for decoders and a
reasonable class of performance for encoders. Since CPB is the most
popular canonical MPEG-1 conformance point, MPEG devices which are not
capable of at least meeting SIF rates are usually not considered to be
true MPEG by industry.
Picture buffers (i.e. "frame stores") and coded data buffering
requirements for MPEG-1 CPB fit just snugly into 4 Mbit of memory
(DRAM).
Who uses constrained parameters bitstreams?
A. Principal CPB applications are Compact Disc video (White Book or
CD-I) and desktop video. Set-top TV decoders fall into a higher
sampling rate category known as "CCIR 601" or "Broadcast rate," which
as a rule of thumb, has sampling dimensions and bandwidth 4 times
that of SIF (Constrained Parameter sample rate limit).
Are there ways of circumventing constrained parameters bitstreams for
SIF class applications and decoders ?
A. Yes, some. Remember that CPB limits pictures by macroblock count
(or pixels/frame). 416 x 240 x 24 Hz sampling rates are still within
these constraints. Deviating from 352 samples/line could throw off many
decoder implementations which possess limited horizontal sample rate
conversion abilities. Some decoders do in fact include a few rate
conversion modes, with a filter usually implemented via binary taps
(shifts and adds). Likewise, the target sample rates are usually
limited or ratios (e.g. 640, 540, 480 pixels/line, etc.). Future MPEG
decoders will likely include on-chip arbitrary sample rate converters,
perhaps capable of operating in the vertical direction (although there
is little need of this in applications using standard TV monitors where
line count is constant, with the possible exception of windowing in
cable box graphical user interfaces).
Also, many CD videos are letterboxed at the 16:9 aspect ratio. The
actual coded and display sampling dimensions are 384 x 216 (note
384/216 = 16/9). These programs are typically movies coded at the more
manageable 24 frames/sec.
Are there any other conformance points like CPB for MPEG-1?
A. Undocumented ones, yes. A second generation of decoder chips
emerged on the market about 1 year after the first wave of SIF-class
decoders. Both LSI Logic and SGS-Thomson introduced CCIR 601 class
MPEG-1 video decoders to fill in the gap between canonical MPEG-1 (SIF)
and the emergence of Main Profile at Main Level (CCIR 601) MPEG-2
decoders. Under non-disclosure agreement, C-Cube had the CL- 950,
although since Q2'94, the CL-9100 is now the full MPEG-2 successor in
production. MPEG-1 decoders in the CCIR 601 class, or Main Level, were
all too often called MPEG-1.5 or MPEG-1++ decoders. For the first year
of operation, the Direct Broadcasting Satellite service in the United
States (Hughes Direct TV and Hubbards USSB) called only upon MPEG-1
syntax to represent interlaced video before switching to full MPEG-2
syntax.
What frame rates are permitted in MPEG?
A limited set is available for the choosing in MPEG-1 and the currently
defined set of Profiles and Levels of MPEG-2, although "tricks" could
be played with Systems-layer Time Stamps to convey non-standard picture
rates. The set is: 23.976 Hz (3-2 pulldown NTSC), 24 Hz (Film), 25 Hz
(PAL/SECAM or 625/60 video), 29.97 (NTSC), 30 Hz (drop-frame NTSC or
component 525/60), 50 Hz (double-rate PAL), 59.97 Hz (double rate
NTSC), and 60 Hz (double-rate, drop-frame NTSC/component 525/60
video).
Only 23.976, 24, 25, 29.97, and 30 Hz are within the conformance space
of Constrained Parameter Bitstreams and Main Level.
What areas can be improved upon to create a better syntax
than MPEG?
Several improvements can be made to the MPEG syntax while remaining
within the framework of block based coding. As implementation
technology improves with time, the ratio of computation to sample rate
can be increased for the same implementation cost. With each
evolutionary stage in the shrinking of the semiconductor lithography
process (line width), more complex coding methods become economically
realizable. Some of the well-known or well-anticipated areas for
improvement are described below:
Intra coding:
For intra pictures, subband methods such as wavelets combined with
improved quantization and entropy coders could gain as much as 2-4 dB
over MPEG Intra pictures. The problem becomes more complex when
considering the coding of Intra Macroblocks in mixed pictures, such as
P or B, since the extend of a subband must, in the simplest of
schemes, be limited to the dimensions of a macroblock.
Prediction error coding
One of the strongest gripes against MPEG is the use of the DCT for
decorrelation of prediction error blocks. One explanation is that the
DCT is suited for the statistical correlation of intra signals, but
less suited for the statistics of prediction error (Non-Intra) signals.
One common proposal is to replace the DCT with a Vector Quantizer.
Prediction error (Non-intra) blocks typically contain far fewer bits
than intra blocks. (The bits that comprise a Non-intra blocks can be
thought of as having been previously distributed over previous blocks
in previous pictures in the form of coefficients and side
information...)
Finer coding unit granularity�s:
The size of the transform block could be made smaller, larger, or both
(myriad of different sizes). Likewise, the size of the motion
compensation block can be made larger or smaller. The cost is more
complex semantics (more decoder complexity) and the overhead bits to
select the block size. Instead of sharing the same side information,
the blocks within the macroblock could be assigned their own motion
vectors, macroblock quantization scale factors, etc.
Many advanced techniques were in investigated by MPEG during the
formative stages of the specification, but were eventually eliminated
for falling below a threshold set for coding gain vs. implementation
complexity. Often, proposals presented a significant departure from the
main stream algorithms under consideration. Each bit added to the
syntax, or rule added to the semantics represents several gates to a
silicon implementation, or from a software perspective, an extra table,
if-then or case statement at multiple points in the decoding program.
What are the similarities and differences between MPEG and
H.263
During its formative stages, H.263 was known as "H.26P" or "H.26X". It
is an ITU-T standard for low-bitrate video and audio teleconferencing.
It is designed to be more efficient (at least 2dB) than H.261 for bit
rates below 64 kbits/sec (ISDN B channel). The primary target bit
rate, approximately 27,000 bits/sec, is the payload rate of the V.34
(a.k.a "V.Fast" or "V.Last") modem standard. In a typical scenario, 20
kbit/sec would be allocated for the video portion, and 6.5 kbit/sec for
the speech portion.
Since the H.261 syntax was defined in 1990, techniques and
implementation power have naturally improved. H.263 collects many of
the advanced methods proposed during MPEGs formative stages into a
syntax which shares a common basis more with MPEG-1 video than with
H.261.
The detailed differences and similarities are summarized below:
Sample rate, precision, and color space:
H.263 pictures are transmitted with QCIF dimensions. MPEG and JPEG
allow nearly any picture size to be described in the headers. A fixed
picture size promotes interoperability by forcing all implementors to
operate at a common rate, rather than by allowing implementors to get
away with whatever lowest sample rate the consumer can be tricked into
buying. Another reason for a fixed sample rate is that, unlike MPEG
which is generic, H.263 is geared towards a specific application
(teleconferencing). Other MPEG applications such as CD Video and Cable
TV define their own fixed parameters. Chromaticy is again YCbCr, 4:2:0
macroblock structure, and 8 bits of uniform sample precision.
[details deferred]
How would you describe MPEG to the Data Compression
expert?
A. MPEG video is a block-based coding scheme.
How does MPEG video really compare to TV, VHS, laserdisc ?
A. VHS picture quality can be achieved for film source video at about 1
million bits per second (with careful application of proprietary
encoding methods). Objective comparison of MPEG to VHS is complex.
The luminance response curve of VHS places -3 dB (50% response, the
common definition of bandlimit) at around analog 2 MHz (digital
equivalent to 200 samples/line). VHS chroma is considerably less dense
in the horizontal direction than MPEG's 4:2:0 signal (compare 80
samples/line equivalent to 176 !!). From a sampling density
perspective, VHS is superior only in the vertical direction (480
luminance lines compared to 240). When other analog factors are taken
into account, such as interfield crosstalk and the TV monitor Kell
factor, the perceptual vertical advantage becomes much less than 2:1.
VHS is also prone to such inconveniences as timing errors (an annoyance
addressed by time base correctors), whereas digital video is fully
discretized. Duplication processes for pre-recorded VHS tapes at high
speeds (5 to 15 times real time playback speed) introduces additional
handicaps. In gist, MPEG-1 at its nominal parameters can match VHSs
sexy low-pass-filtered look, but for critical sequences, is probably
overall inferior to a well mastered, well duplicated VHS tape.
With careful coding schemes, broadcast NTSC quality can be approximated
at about 3 Mbit/sec, and PAL quality at about 4 Mbit/sec for film
source video. Of course, sports sequences with complex spatial-
temporal activity should be treated with higher bit rates, in the
neighborhood of 5 and 6 Mbit/sec. Laserdisc is perhaps the most
difficult medium to make comparisons with.
First, the video signal encoded onto a laserdisc is composite, which
lends the signal to the familiar set of artifacts (reduced color
accuracy of YIQ, moirse patterns, crosstalk, etc). The medium's
bandlimited signal is often defined by laserdisc player manufacturers
and main stream publications as capable of rendering up to 425 TVL (or
frequencies with Nyquist at 567 samples/line). An equivalent component
digital representation would therefore have sampling dimensions of 567
x 480 x 30 Hz. The carrier-to-noise ratio of a laserdisc video signal
is typically better than 48 dB. Timing accuracy is excellent,
certainly better than VHS. Yet some of the clean characteristics of
laserdisc can be simulated with MPEG-1 signals as low as 1.15 Mbit/sec
(SIF rates), especially for those areas of medium detail (low spatial
activity) in the presence of uniform motion (affine motion vector
fields). The appearance of laserdisc or Super VHS quality can therefore
be obtained for many video sequences with low bit rates, but for the
more general class of images sequences, a bit rate ranging from 3 to 6
Mbit/sec is necessary.
What are the typical coded sizes for the MPEG frames?
Typical bit sizes for the three different picture types:
Level
I
P
B
Average
30 Hz SIF
@ 1.15 Mbit/sec
150,000
50,000
20,000
38,000
30 Hz CCIR 601
@ 4 Mbit/sec
400,000
200,000
80,000
130,000
Note: the above example is taken from a standard test sequence coded by
the Test Model method, with an I frame distance of 15 (N = 15), and a P
frame distance of 3 (M = 3).
Of course, among differing source material, scene changes, and use of
advanced encoder models these numbers can be significantly different.
At what bitrates is MPEG-2 video optimal?
The Test subgroup has defined a few example "Sweet spot" sampling
dimensions and bit rates for MPEG-2:
Dimensions
Coded rate
Application
352x480x24 Hz
(progressive)
2 Mbit/sec
Equivalent to VHS quality. Intended for film source video. Half
horizontal 601(HHR). Looks almost broadcast NTSC quality
544x480x30 Hz
(interlaced).
4 Mbit/sec
PAL broadcast quality (nearly full capture of 5.4 MHz luminance
signal). 544 samples matches the width of a 4:3 picture windowed
within 720 sample/line 16:9 aspect ratio via pan&scan
704x480x30
Hz.(interlaced)
6 Mbit/sec
Full CCIR 601 sampling dimensions
These numbers may be too ambitious. Bit rates of 3, 6, and 8 Mbit/sec
respectively provide transparent quality for the above application
examples when generated by a reasonably sophisticated encoder.
Why does film perform so well with MPEG ?
1. The frame rate is 24 Hz (instead of 30 Hz) which is a savings of
some 20%.
2. Film source video is inherently progressive. Hence no fussy
interlaced spectral frequencies.
3. The pre-digital source was severely oversampled (compare 352 x 240
SIF to 35 millimeter film at, say, 3000 x 2000 samples). This can
result in a very high quality signal, whereas most video cameras do not
oversample, especially in the vertical direction.
4. Finally, the spatial and temporal modulation transfer function (MTF)
characteristics (motion blur, etc) of film are more amenable to the
transform and quantization methods of MPEG.
What is the best compression ratio for MPEG ?
The MPEG sweet spot is about 1.2 bits/pel Intra and 0.35 bits/pixel
inter. Experimentation has shown that intra frame coding with the
familiar DCT-Quantization-Huffman hybrid algorithm achieves optimal
performance at about an average of 1.2 bits/sample or about 6:1
compression ratio. Below this point, artifacts become non-transparent.
Is there an MPEG file format?
The traditional descriptors that file formats provide in headers, such
image height, width, color space, etc., are already embedded within the
MPEG bitstream in the sequence header. Directory file formats are
described in the White Book and DVD specifications.
What is the Digital Video Disc (DVD) ?
In 1994, Toshiba united with Thomson Consumer Electronics, Pioneer, and
a handful of Hollywood studios to define a new 12 cm diameter compact
disc format for broadcast rate digital video. The new format basically
increases the effective areal storage density over the 1982 Red Book
format by some 6:1 (800 Mbytes vs 5 GBytes). This is achieved through
a combination of shorter laser wavelength, finer track pitch, inter-pit
pitch, and better optics. The thickness of the disc is reduced from the
Red Book's 1.2 millimeters to 0.6 millimeters. However, the new format
can be glue two 0.6 mm thick discs back-to-back, forming a double- size
disc 1.2 mm thick with a total capacity of 10 Gbytes. A two hour movie,
encoded onto only one side, would contain a video bistream average at 5
Mbit/sec. Or 10 Mbit/sec if distributed on both sides of a disc. Most
of the 6:1 gain is achieved though more efficient encoding of bits onto
the disc. Only a 2:1 factor comes purely from the reduction in
wavelength.
By comparison, today's double-sided analog video laserdiscs have a
diameter of 30 cm (571 cm^2 of usable area), and a thickness of 2.4
millimeters. Storage capacity is a maximum of 65 minutes per side.
A future potential format for HDTV may employ a blue wavelength laser
(0.4 microns), offering another 2:1 increase in areal density, or 20
Gbytes total. Other alternatives include larger disc sizes. For
example, if bit coding at DVD areal densities were applied to the
familiar 30 cm disc, the average bitrate for the 65 minutes of video
per side would be nearly 70 Mbit/sec !!
What is the MPEG committee ?
In fact, MPEG is a nickname. The official title is: ISO/IEC JTC1 SC29 WG11.
ISO: International Organization for Standardization
IEC: International Electrotechnical Commission
JTC1: Joint Technical Committee 1
SC29: Sub-committee 29
WG11: Working Group 11 (moving pictures with... uh, audio)
What ever happened to MPEG-3 ?
MPEG-3 was to have targeted HDTV applications with sampling dimensions
up to 1920 x 1080 x 30 Hz and coded bitrates between 20 and 40
Mbit/sec. It was later discovered that with some (syntax compatible)
fine tuning, MPEG-2 and MPEG-1 syntax worked very well for HDTV rate
video. The key is to maintain an optimal balance between sample rate
and coded bit rate.
Also, the standardization window for HDTV was rapidly closing. Europe
and the United States were on the brink of committing to
analog-digital subnyquist hybrid algorithms (D-MAC, MUSE, et al). By
1992, European all-digital projects such as HD-DIVINE and VADIS
demonstrated better picture quality with respect to bandwidth using the
MPEG syntax. In the United States, the Sarnoff/NBC/Philips/Thomson
HDTV consortium had used MPEG-1 syntax from the beginning of its
all-digital proposal, and with the exception of motion artifacts (due
to limited search range in the encoder), was deemed to have the best
picture quality of all three digital proponents in the early 1993
bake-off. HDTV is now part of the MPEG-2 High-1440 Level and High Level
toolkit.
Why bother having an MPEG-2 ?
A. MPEG-1 was optimized for CD-ROM or applications at about 1.5
Mbit/sec. Video was strictly non- interlaced (i.e. progressive). The
international cooperation executed well enough for MPEG-1, that the
committee began to address applications at broadcast TV sample rates
using the CCIR 601 recommendation (720 samples/line by 480 lines per
frame by 30 frames per second or about 15.2 million samples/sec
including chroma) as the reference.
Unfortunately, today's TV scanning pattern is interlaced. This
introduces a duality in block coding: do local redundancy areas
(blocks) exist exclusively in a field or a frame.(or a particle or
wave) ? The answer of course is that some blocks are one or the other
at different times, depending on motion activity. The additional man
years of experimentation and implementation between MPEG-1 and MPEG-2
improved the method of block-based transform coding.
It is often remarked that MPEG-2 spent several hundred man years and
10s of millions of dollars yet only gained 20% coding efficiency over
MPEG-1 for interlaced video signals. However, the collaborative
process brought companies together, and from that came a standard well
agreed upon. In many ways, the political achievement dwarfs the
technical one. Also, MPEG-2 was exploratory. Coding of interlaced
video was unknown territory. It took some considerable convincing to
demonstrate that a simple syntax, akin to MPEG-1, was as efficient as
other proposals. Left by themselves, each company would probably have
produced a diverse scope of syntax.
Is MPEG patented ?
Many of the companies which participated in the MPEG committee have
indicated that they hold patents to fundamental elements of the MPEG
syntax and semantics. Already, the group known as the "IRT consortium"
(CCETT, IRT, et al) have defined royalty fees and licensing agreements
for OEMs of MPEG Layer I and II audio encoders and decoders. The fee
is $1 USD per audio channel in small quantities, and $0.50 USD per
channel in large quantities.
A royalty and licensing agreement has yet to be reached among holders
of Video and Systems patents, however the figure has already been
agreed upon, ranging from $3 to $4 per implementation. Whether it is
retroactively applicable or not to products already sold, or whether it
is possible to avoid the patents via approximation techniques, is not
known. The non-profit organization,CableLabs (Boulder, Colorado), is
responsible for leading the MPEG Intellectual Property Rights effort
(known canonically as the "MPEG Patent Pool."). An agreement is
expected by mid 1995.
In order to reach the IS (International Standard) document stage, all
parties must have sent in a letter to ISO stating they agree to license
their intellectual property on fair and reasonable terms,
indiscriminately. For MPEG-1 and MPEG-2, this was accomplished in mid
1993.
Companies which hold patents often cross-license each other. Each
party does not have to pay royalties to one another.
What is White Book
The White Book specifies the file structure and indexing of multiplexed
MPEG video and audio streams. White Book also specifies the Karaoke
application's reference table which describes programs and their sector
locations. At the lowest layer, White Book builds upon the CD-ROM XA
spec.. Extension data includes screen pointing devices, address list of
all Intra pictures within a program, CD version number, Closed Caption
data, and information indexing of MPEG still pictures.
The specific MPEG parameter definitions of White Book are:
Audio coding method: MPEG-1 Layer II
Sampling rate: 44.1 kHz
Coded bit rate: 224 Kbits/sec
Mode: stereo, dual channel, or intensity stereo
Video coding method: MPEG-1
Permitted sample rates:
352 pixels/line x 240 lines/frame x 29.97 frames/sec (NTSC rate)
352 pixels/line x 240 lines/frame x 23.976 frames/sec (NTSC film rate)
352 pixels/line x 288 lines/frame x 25 frame/sec (PAL rate)
Maximum bitrate: 1.1519291 bits/sec
Recommendations include:
pixel aspect ratios: 1.0950 (352x240) or 0.9157 (352 x 288)
Intra pictures be placed at least once every 2 seconds.
Still pictures: ("Intra" picture_coding_type only)
Normal res: 352 x 240 or 352 x 288 (maximum 46 Kbytes coded size)
Double res: 704 x 480 or 704 x 576 (maximum 224 Kbytes coded size)
The other books are:
Red Book: this is the original Compact Disc Audio specification (circa
1980). All other books (Yellow, Green, Orange, White) are identical at
the low-level, sharing a common base with Red Book. This grandfather
specification defines sectors, tracks, and channel coding (8/14 EFM
outer forward error correction (FEC), 8-bit polynomial interleaved
Reed-Soloman inner forward error correction, etc), and physical
parameters (disc diameter 12 cm, laser wavelength 0.8 microns, track
pitch, land-to-pit spacing, digital modulation, etc.).
Yellow Book: first CD-ROM specification (circa 1986). Later appended
by the CD-ROM XA spec.
Green Book: CD-I (Compact Disc Interactive).
Orange Book: Kodak Photo CD
ISO 9660: (circa 1988) describes file structure for CD-ROM XA (circa
1988). Similar to MS-DOS, filenames are case insensitive and limited to
8 characters, and 3 extension characters (8.3 format). Many CD-ROMs
containing MPEG are nothing more than Yellow Book CD which treat
multiplexed video and audio bitstreams as an ordinary file.
Further information can be retrieved from:
Philips Consumer Electronics B.V.
Coordination Office Optical & Magnetic Media Systems
Building SWA-1
P.O. Box 80002
5600 JB Eindhoven
The Netherlands
Tel: +31 40 736409
Fax: +31 40 732113
What are some typical picture sizes and their associated
applications ?
352 x 240 SIF. CD WhiteBook Movies, video games.
352 x 480 HHR. VHS equivalent
480 x 480 Bandlimited (4.2 Mhz) broadcast NTSC.
544 x 480 Laserdisc, D-2, Bandlimited PAL/SECAM.
640 x 480 Square pixel NTSC
720 x 480 CCIR 601. Studio D-1. Upper limit of Main Level.
Future topics:
How are MPEG video and audio streams synchronized?
What is Digital Video Cassette (DVC) ?
How does the D-VHS format encode MPEG signals?
What is MPEG-4 ?
The high level and low level differences between MPEG, JPEG, H.261, and H.263
MPEG in applications
More on DVD.
Details on DVB
Implementations (semiconductor chips)
Software Complexity and performance. Well known speedup methods.
MPEG software on the Internet (audio, video, systems)
Specific MPEG articles in literature.
Current activities of MPEG-4
MPEG Compliance bitstreams
-----
cfogg@chromatic.com